Analyze Speech & Language with Google APIs: Challenge Lab

A passionate full-stack developer from @ePlus.DEV
Overview
In a challenge lab you’re given a scenario and a set of tasks. Instead of following step-by-step instructions, you will use the skills learned from the labs in the course to figure out how to complete the tasks on your own! An automated scoring system (shown on this page) will provide feedback on whether you have completed your tasks correctly.
When you take a challenge lab, you will not be taught new Google Cloud concepts. You are expected to extend your learned skills, like changing default values and reading and researching error messages to fix your own mistakes.
To score 100% you must successfully complete all tasks within the time period!
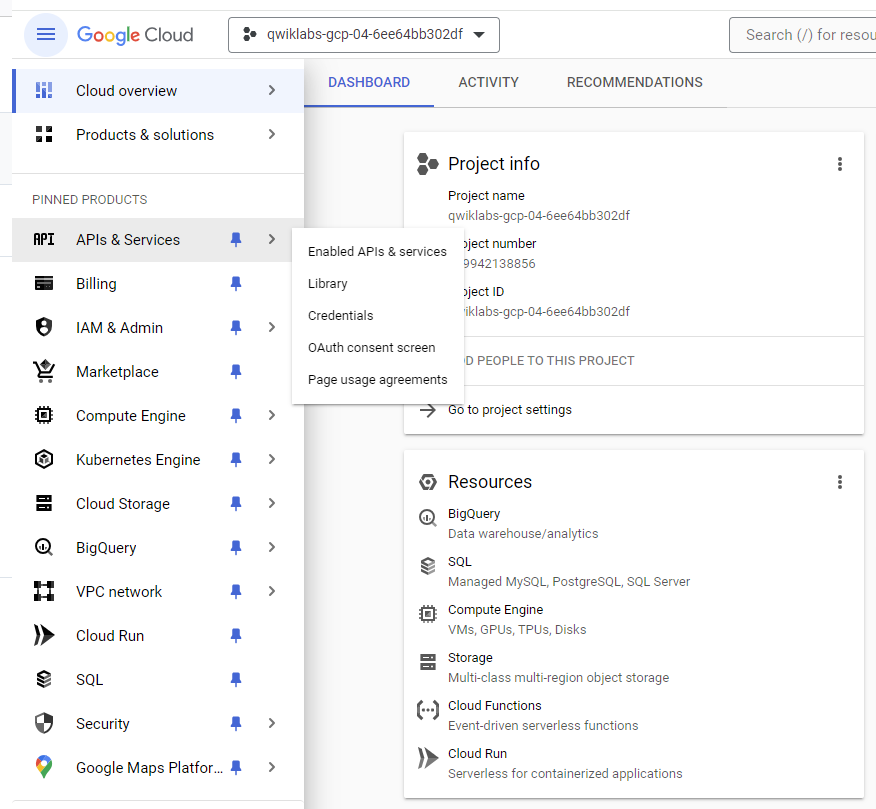
Task 1. Create an API key
Since you use curl to send a request to the Natural Language API, you must generate an API key to pass in your request URL.
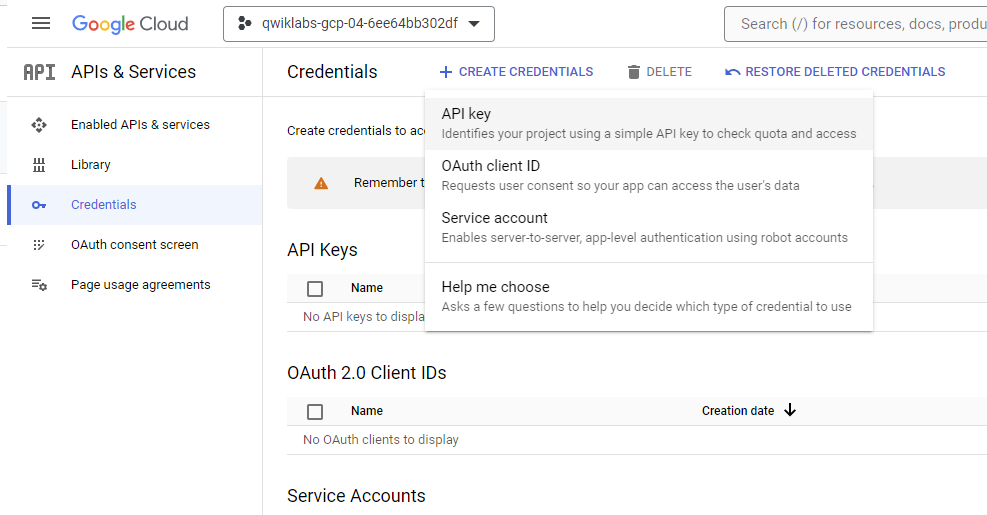
To create an API key, in the Cloud Console, select Navigation menu > APIs & Services > Credentials.
Click Create credentials and select API key.
Copy the generated API key and click Close.

Task 2. Make an entity analysis request and call the Natural Language API
export API_KEY=<YOUR_API_KEY>
vim nl_request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"With approximately 8.2 million people residing in Boston, the capital city of Massachusetts is one of the largest in the United States."
},
"encodingType":"UTF8"
}
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @nl_request.json > nl_response.json
Task 3. Create a speech analysis request and call the Speech API
vim speech_request.json
{
"config": {
"encoding":"FLAC",
"languageCode": "en-US"
},
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
}
curl -s -X POST -H "Content-Type: application/json" --data-binary @speech_request.json \
"https://speech.googleapis.com/v1/speech:recognize?key=${API_KEY}"
curl -s -X POST -H "Content-Type: application/json" --data-binary @speech_request.json \
"https://speech.googleapis.com/v1/speech:recognize?key=${API_KEY}" > speech_response.json
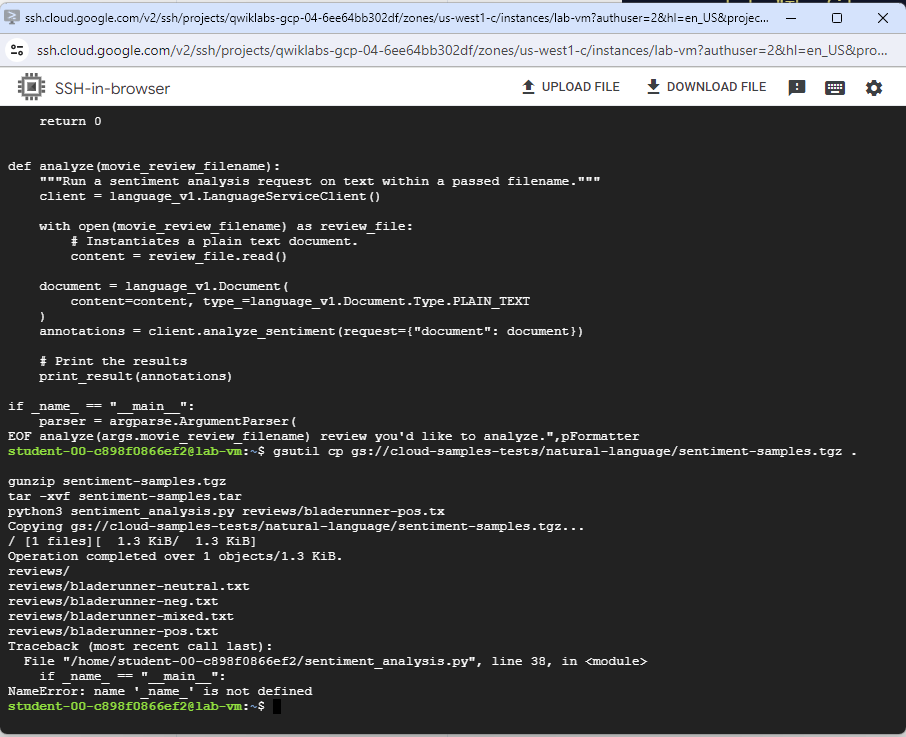
Task 4. Analyze sentiment with the Natural Language API
cat > sentiment_analysis.py <<EOF
import argparse
from google.cloud import language_v1
def print_result(annotations):
score = annotations.document_sentiment.score
magnitude = annotations.document_sentiment.magnitude
for index, sentence in enumerate(annotations.sentences):
sentence_sentiment = sentence.sentiment.score
print(
f"Sentence {index} has a sentiment score of {sentence_sentiment}"
)
print(
f"Overall Sentiment: score of {score} with magnitude of {magnitude}"
)
return 0
def analyze(movie_review_filename):
"""Run a sentiment analysis request on text within a passed filename."""
client = language_v1.LanguageServiceClient()
with open(movie_review_filename) as review_file:
# Instantiates a plain text document.
content = review_file.read()
document = language_v1.Document(
content=content, type_=language_v1.Document.Type.PLAIN_TEXT
)
annotations = client.analyze_sentiment(request={"document": document})
# Print the results
print_result(annotations)
if _name_ == "__main__":
parser = argparse.ArgumentParser(
description=__doc__, formatter_class=argparse.RawDescriptionHelpFormatter
)
parser.add_argument(
"movie_review_filename",
help="The filename of the movie review you'd like to analyze.",
)
args = parser.parse_args()
analyze(args.movie_review_filename)
EOF
gsutil cp gs://cloud-samples-tests/natural-language/sentiment-samples.tgz .
gunzip sentiment-samples.tgz
tar -xvf sentiment-samples.tar
python3 sentiment_analysis.py reviews/bladerunner-pos.tx