Build an Application to Generate Text Embeddings with Gemini on Vertex AI (Solution)
A passionate full-stack developer from @ePlus.DEV
Challenge scenario
Scenario: You are a data scientist working on a natural language processing (NLP) project that involves embedding text data using a pre-trained language model. Your goal is to generate vector embeddings for given text phrases to use them in a downstream machine learning task, such as text classification or semantic search.
You need to write a Python script that loads a pre-trained text embedding model, computes embeddings for a given sentence, and prints out the length of the resulting embedding vector for analysis.:
Task: Develop a Python function named text_embedding(prompt). This function should invoke the text-embedding-005 model using the supplied prompt, generate the response.
Follow these steps to interact with the Generative AI APIs using Vertex AI Python SDK.
Click File > New File to open a new file within the Code Editor.
Write the Python code to use Google's Vertex AI SDK to interact with the pre-trained Text Generation AI model.
Create and save the python file.
Execute the Python file by invoking the below command by replacing the FILE_NAME inside the terminal within the Code Editor pane to view the output.
/usr/bin/python3 /FILE_NAME.py
Click Check my progress to verify the objective.
Send text embedding requests to Gen AI and receive a response
Solution of Lab
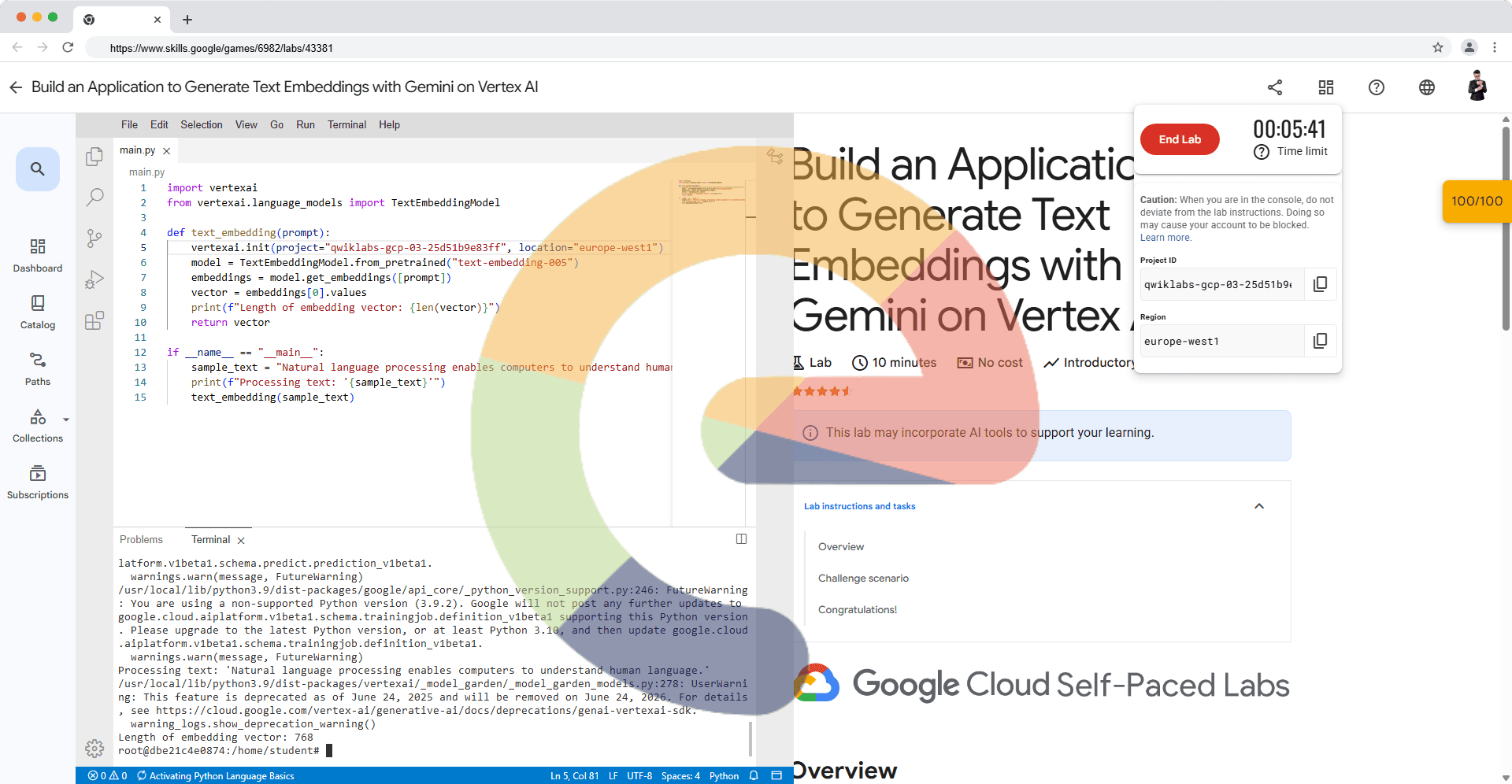
import vertexai
from vertexai.language_models import TextEmbeddingModel
def text_embedding(prompt):
vertexai.init(project="YOUR_PROJECT_ID", location="us-central1")
model = TextEmbeddingModel.from_pretrained("text-embedding-005")
embeddings = model.get_embeddings([prompt])
vector = embeddings[0].values
print(f"Length of embedding vector: {len(vector)}")
return vector
if __name__ == "__main__":
sample_text = "Natural language processing enables computers to understand human language."
print(f"Processing text: '{sample_text}'")
text_embedding(sample_text)


/usr/bin/python3 /main.py