
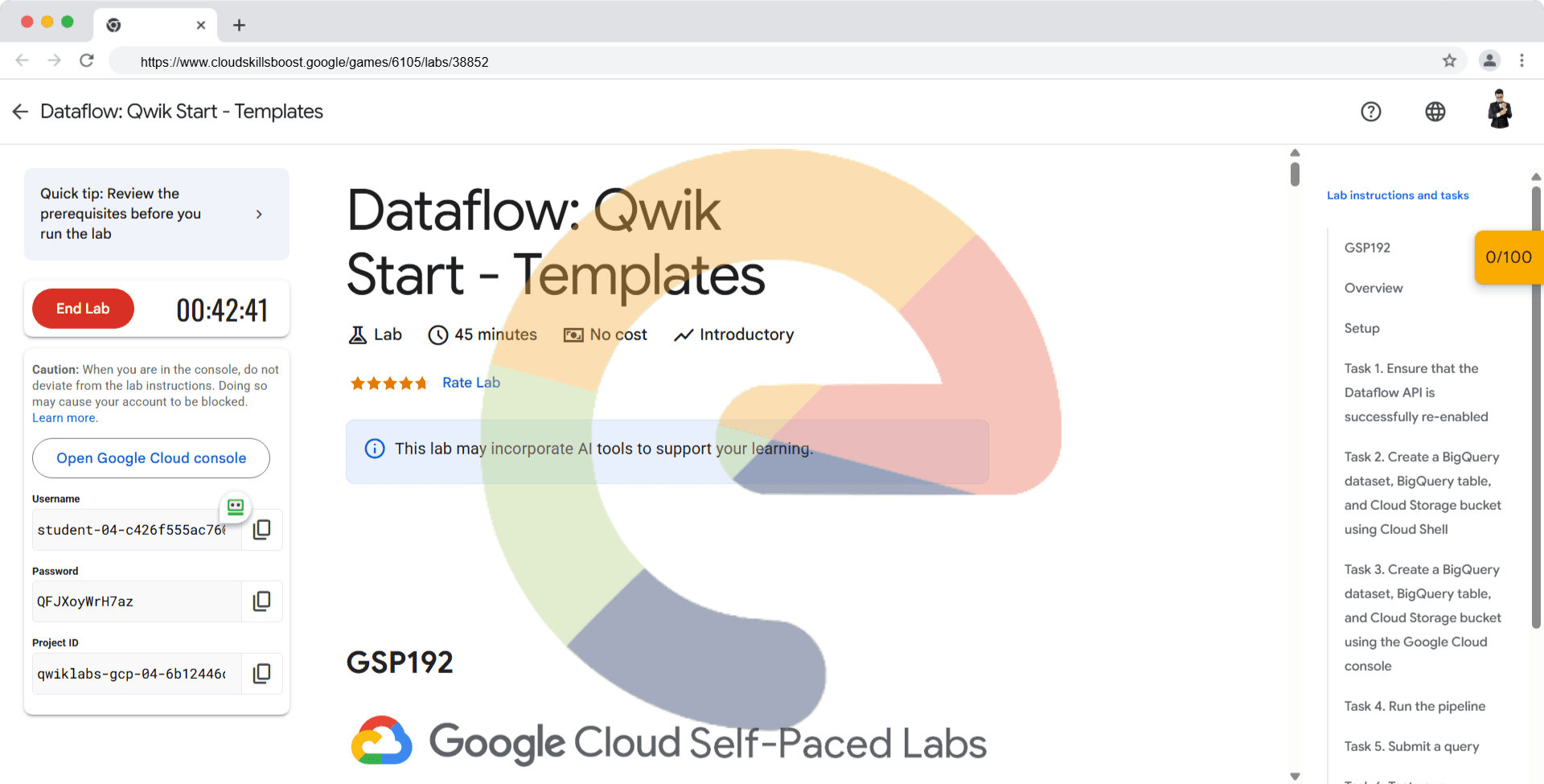
Dataflow: Qwik Start - Templates - GSP192
D
A passionate full-stack developer from @ePlus.DEV
Search for a command to run...
A passionate full-stack developer from @ePlus.DEV
No comments yet. Be the first to comment.
Quick and practical tips to help users optimize tasks, improve skills, and solve common problems effectively across various areas like tech, lifestyle, productivity, and more.
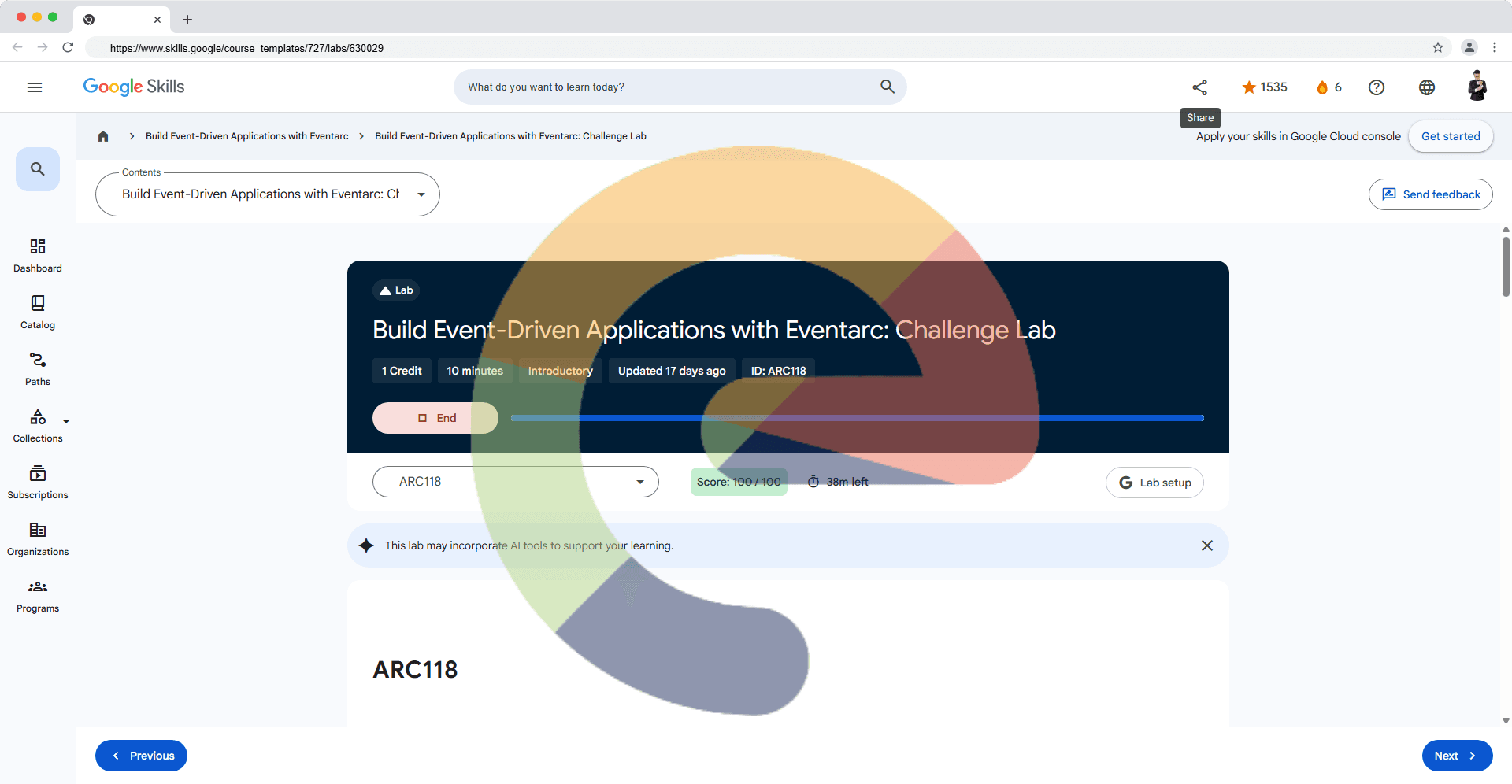
Overview In a challenge lab you’re given a scenario and a set of tasks. Instead of following step-by-step instructions, you will use the skills learned from the labs in the course to figure out how to
Một bản tin giúp Developer cập nhật nhanh AI, Cloud, Open Source và những công nghệ đáng chú ý trong ngày. 📌 Executive Summary OpenAI công bố báo cáo mới về cách AI đang làm thay đổi phạm vi công

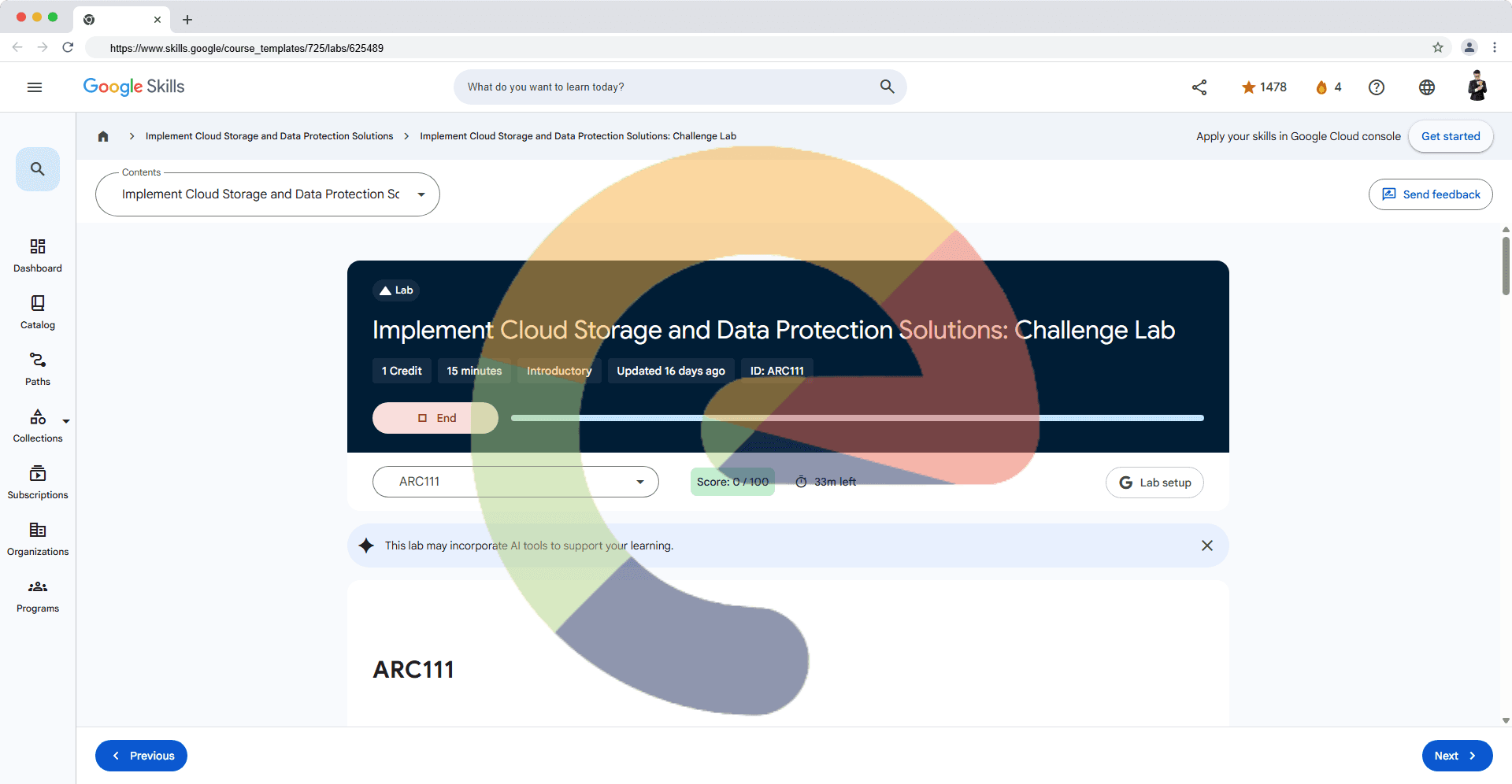
Overview In a challenge lab you’re given a scenario and a set of tasks. Instead of following step-by-step instructions, you will use the skills learned from the labs in the course to figure out how to
Một bản tin giúp Developer cập nhật nhanh AI, Cloud, Open Source và những công nghệ đáng chú ý trong ngày. 📌 Executive Summary Anthropic bổ sung khả năng thay đổi tool giữa cuộc hội thoại mà không

Một bản tin giúp Developer cập nhật nhanh AI, Cloud, Open Source và những công nghệ đáng chú ý trong ngày. 📌 Executive Summary Claude Opus 5 bắt đầu được triển khai trên GitHub Copilot cho các tác

In this lab, you learn how to create a streaming pipeline using one of Google's Dataflow templates. More specifically, you use the Pub/Sub to BigQuery template, which reads messages written in JSON from a Pub/Sub topic and pushes them to a BigQuery table. You can find the documentation for this template in the Get started with Google-provided templates Guide.
You are given the option to use the Cloud Shell command line or the Cloud console to create the BigQuery dataset and table. Pick one method to use, then continue with that method for the rest of the lab. If you want experience using both methods, run through this lab a second time.
Create a BigQuery dataset and table
Create a Cloud Storage bucket
Create a streaming pipeline using the Pub/Sub to BigQuery Dataflow template
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources are made available to you.
This hands-on lab lets you do the lab activities in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
Note: Use an Incognito (recommended) or private browser window to run this lab. This prevents conflicts between your personal account and the student account, which may cause extra charges incurred to your personal account.
Note: Use only the student account for this lab. If you use a different Google Cloud account, you may incur charges to that account.
Click the Start Lab button. If you need to pay for the lab, a dialog opens for you to select your payment method. On the left is the Lab Details pane with the following:
The Open Google Cloud console button
Time remaining
The temporary credentials that you must use for this lab
Other information, if needed, to step through this lab
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account.
If necessary, copy the Username below and paste it into the Sign in dialog.
student-04-c426f555ac76@qwiklabs.net
You can also find the Username in the Lab Details pane.
Click Next.
Copy the Password below and paste it into the Welcome dialog.
QFJXoyWrH7az
You can also find the Password in the Lab Details pane.
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials.
Note: Using your own Google Cloud account for this lab may incur extra charges.
Click through the subsequent pages:
Accept the terms and conditions.
Do not add recovery options or two-factor authentication (because this is a temporary account).
Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.
Note: To access Google Cloud products and services, click the Navigation menu or type the service or product name in the Search field.

Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
Click Activate Cloud Shell at the top of the Google Cloud console.
Click through the following windows:
Continue through the Cloud Shell information window.
Authorize Cloud Shell to use your credentials to make Google Cloud API calls.
When you are connected, you are already authenticated, and the project is set to your Project_ID, qwiklabs-gcp-04-6b12446d8944. The output contains a line that declares the Project_ID for this session:
Your Cloud Platform project in this session is set to qwiklabs-gcp-04-6b12446d8944
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
gcloud auth list
Output:
ACTIVE: *
ACCOUNT: student-04-c426f555ac76@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Output:
[core]
project = qwiklabs-gcp-04-6b12446d8944
Note: For full documentation of gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
To ensure access to the necessary API, restart the connection to the Dataflow API.
In the Cloud Console, enter "Dataflow API" in the top search bar. Click on the result for Dataflow API.
Click Manage.
Click Disable API.
If asked to confirm, click Disable.
When the API has been enabled again, the page will show the option to disable.
Test completed task
Click Check my progress to verify your performed task.
Disable and re-enable the Dataflow API.
Check my progress
Let's first create a BigQuery dataset and table.
Note: This task uses the bq command-line tool. Skip down to Task 3 if you want to complete these steps using the Cloud console.
taxirides:bq mk taxirides
Your output should look similar to:
Dataset '<myprojectid:taxirides>' successfully created
</myprojectid:taxirides>
Test completed task
Click Check my progress to verify your performed task. If you have successfully created a BigQuery dataset, you will see an assessment score.
Create a BigQuery Dataset (name: taxirides).
Check my progress
Now that you have your dataset created, you'll use it in the following step to instantiate a BigQuery table.
bq mk \
--time_partitioning_field timestamp \
--schema ride_id:string,point_idx:integer,latitude:float,longitude:float,\
timestamp:timestamp,meter_reading:float,meter_increment:float,ride_status:string,\
passenger_count:integer -t taxirides.realtime
Your output should look similar to:
Table 'myprojectid:taxirides.realtime' successfully created
Test completed task
Click Check my progress to verify your performed task. If you have successfully created a table in BigQuery dataset, you will see an assessment score.
Create a table in BigQuery Dataset.
Check my progress
On its face, the bq mk command looks a bit complicated. However, with some assistance from the BigQuery command-line documentation, we can break down what's going on here. For example, the documentation tells us a little bit more about schema:
[FIELD]:[DATA_TYPE], [FIELD]:[DATA_TYPE].In this case, we are using the latter—a comma-separated list.
Now that we have our table instantiated, let's create a bucket.
Use the Project ID as the bucket name to ensure a globally unique name: qwiklabs-gcp-04-6b12446d8944
export BUCKET_NAME=qwiklabs-gcp-04-6b12446d8944
gsutil mb gs://$BUCKET_NAME/
Test completed task
Click Check my progress to verify your performed task. If you have successfully created a Cloud Storage bucket, you will see an assessment score.
Create a Cloud Storage bucket.
Check my progress
Once you've made your bucket, scroll down to the Run the Pipeline section.
Note: Do not complete Task 3 if you completed Task 2, which includes the same tasks in the command line!
From the left-hand menu, in the Big Data section, click on BigQuery.
Then click Done.
Click on the three dots next to your project name under the Explorer section, then click Create dataset.
Input taxirides as your dataset ID:
Select us (multiple regions in United States) in Data location.
Leave all of the other default settings in place and click CREATE DATASET.
Test completed task
Click Check my progress to verify your performed task. If you have successfully created a BigQuery dataset, you will see an assessment score.
Create a BigQuery Dataset (name: taxirides).
Check my progress
You should now see the taxirides dataset underneath your project ID in the left-hand console.
Click on the three dots next to taxirides dataset and select Open.
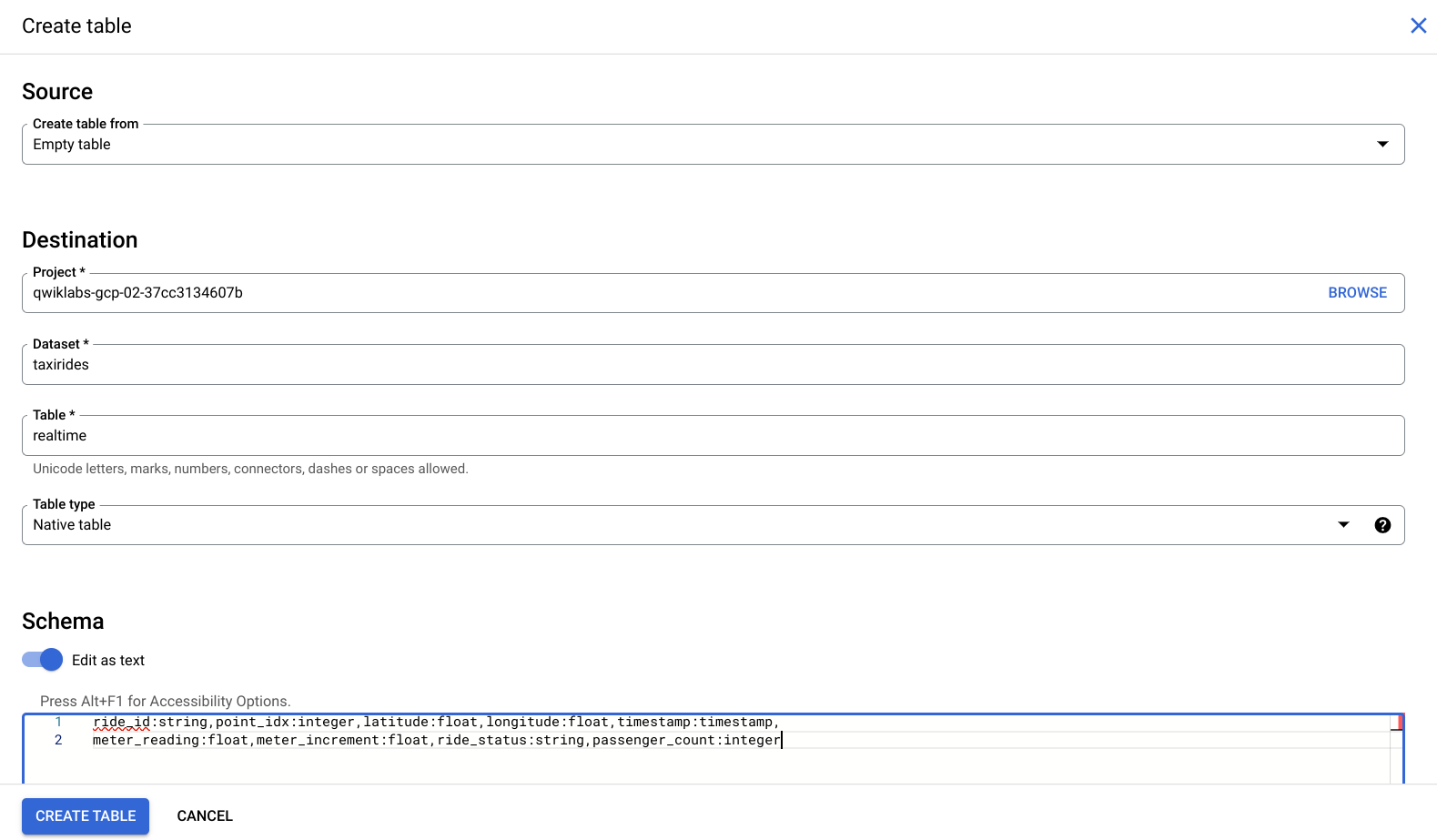
Then select CREATE TABLE in the right-hand side of the console.
In the Destination > Table Name input, enter realtime.
Under Schema, toggle the Edit as text slider and enter the following:
ride_id:string,point_idx:integer,latitude:float,longitude:float,timestamp:timestamp,
meter_reading:float,meter_increment:float,ride_status:string,passenger_count:integer
Your console should look like the following:
Test completed task
Click Check my progress to verify your performed task. If you have successfully created a table in BigQuery dataset, you will see an assessment score.
Create a table in BigQuery Dataset.
Check my progress
Go back to the Cloud Console and navigate to Cloud Storage > Buckets > Create bucket.
Use the Project ID as the bucket name to ensure a globally unique name: qwiklabs-gcp-04-6b12446d8944
Leave all other default settings, then click Create.
Test completed task
Click Check my progress to verify your performed task. If you have successfully created a Cloud Storage bucket, you will see an assessment score.
Create a Cloud Storage bucket.
Check my progress
Deploy the Dataflow Template:
gcloud dataflow jobs run iotflow \
--gcs-location gs://dataflow-templates-us-east1/latest/PubSub_to_BigQuery \
--region us-east1 \
--worker-machine-type e2-medium \
--staging-location gs://qwiklabs-gcp-04-6b12446d8944/temp \
--parameters inputTopic=projects/pubsub-public-data/topics/taxirides-realtime,outputTableSpec=qwiklabs-gcp-04-6b12446d8944:taxirides.realtime
In the Google Cloud Console, on the Navigation menu, click Dataflow > Jobs, and you will see your dataflow job.
Please refer the document for more information.
Note: You may need to wait a minute for the activity tracking to complete.
Test completed task
Click Check my progress to verify your performed task. If you have successfully run the Dataflow pipeline, you will see an assessment score.
Run the Pipeline.
Check my progress
You'll watch your resources build and become ready for use.
Now, let's go view the data written to BigQuery by clicking on BigQuery found in the Navigation menu.
Note: You may have to wait a few minutes for the data to populate in the BigQuery table.
You can submit queries using standard SQL.
SELECT * FROM `qwiklabs-gcp-04-6b12446d8944.taxirides.realtime` LIMIT 1000
If you run into any issues or errors, run the query again (the pipeline takes a minute to start up.)
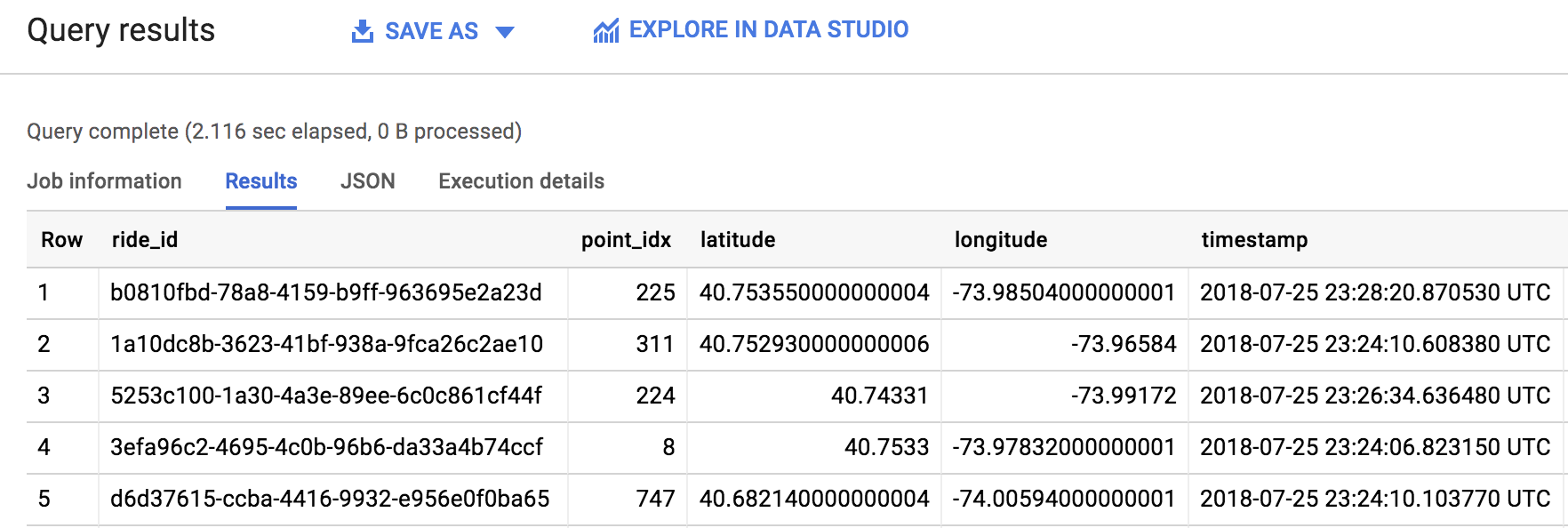
Great work! You just pulled 1000 taxi rides from a Pub/Sub topic and pushed them to a BigQuery table. As you saw firsthand, templates are a practical, easy-to-use way to run Dataflow jobs. Be sure to check out, in the Dataflow Documentation, some other Google Templates in the Get started with Google-provided templates Guide.
Below are multiple choice questions to reinforce your understanding of this lab's concepts. Answer them to the best of your abilities.
Google Cloud Dataflow supports batch processing.
True
False
Which Dataflow Template used in the lab to run the pipeline?
Bulk Compress Cloud Storage Files
Cloud Storage Text to BigQuery
Pub/Sub to BigQuery
curl -LO raw.githubusercontent.com/ePlus-DEV/storage/refs/heads/main/labs/GSP192/lab.sh
source lab.sh