Dataproc: Qwik Start - Console
A passionate full-stack developer from @ePlus.DEV
Overview
Dataproc is a fast, easy-to-use, fully-managed cloud service for running Apache Spark and Apache Hadoop clusters in a simpler, more cost-efficient way. Operations that used to take hours or days take seconds or minutes instead. Create Dataproc clusters quickly and resize them at any time, so you don't have to worry about your data pipelines outgrowing your clusters.
This lab shows you how to use the Google Cloud console to create a Dataproc cluster, run a simple Apache Spark job in the cluster, and then modify the number of workers in the cluster.
Task 1. Create a cluster
In the Cloud Platform Console, select Navigation menu > Dataproc > Clusters, then click Create cluster.
Click Create for Cluster on Compute Engine.
Set the following fields for your cluster and accept the default values for all other fields:
Note: In the Configure nodes section ensure both the Master node and Worker nodes are set to the correct Machine Series and Machine Type
| Field | Value |
| Name | example-cluster |
| Region | us-east4 |
| Zone | us-east4-a |
| Machine Series | E2 |
| Machine Type | e2-standard-2 |
| Number of Worker Nodes | 2 |
| Primary disk size | 30 GB |
| Internal IP only | Deselect "Configure all instances to have only internal IP addresses" |
Note: A Zone is a special multi-region namespace that is capable of deploying instances into all Google Compute zones globally. You can also specify distinct regions, such as us-central1 or europe-west1, to isolate resources (including VM instances and Cloud Storage) and metadata storage locations utilized by Cloud Dataproc within the user-specified region.
- Click Create to create the cluster.
Your new cluster will appear in the Clusters list. It may take a few minutes to create, the cluster Status shows as Provisioning until the cluster is ready to use, then changes to Running.
Answer
export REGION=
export ZONE=
gcloud dataproc clusters create example-cluster \
--region=$REGION \
--zone=$ZONE \
--master-machine-type=e2-standard-2 \
--master-boot-disk-size=50GB \
--num-workers=2 \
--worker-machine-type=e2-standard-2 \
--worker-boot-disk-size=50GB
Task 2. Submit a job
To run a sample Spark job:
Click Jobs in the left pane to switch to Dataproc's jobs view, then click Submit job.
Set the following fields to update Job. Accept the default values for all other fields:
| Field | Value |
| Region | us-east4 |
| Cluster | example-cluster |
| Job type | Spark |
| Main class or jar | org.apache.spark.examples.SparkPi |
| Jar files | file:///usr/lib/spark/examples/jars/spark-examples.jar |
| Arguments | 1000 (This sets the number of tasks.) |
- Click Submit.
Note: How the job calculates Pi: The Spark job estimates a value of Pi using the Monte Carlo method. It generates x,y points on a coordinate plane that models a circle enclosed by a unit square. The input argument (1000) determines the number of x,y pairs to generate; the more pairs generated, the greater the accuracy of the estimation. This estimation leverages Cloud Dataproc worker nodes to parallelize the computation. For more information, see Estimating Pi using the Monte Carlo Method and see JavaSparkPi.java on GitHub.
Your job should appear in the Jobs list, which shows your project's jobs with its cluster, type, and current status. Job status displays as Running, and then Succeeded after it completes.
Answer
gcloud dataproc jobs submit spark \
--region=$REGION \
--cluster=example-cluster \
--class=org.apache.spark.examples.SparkPi \
--jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \
-- 1000
Task 3. View the job output
To see your completed job's output:
Click the job ID in the Jobs list.
Select LINE WRAP to
ONor scroll all the way to the right to see the calculated value of Pi. Your output, with LINE WRAPON, should look something like this:
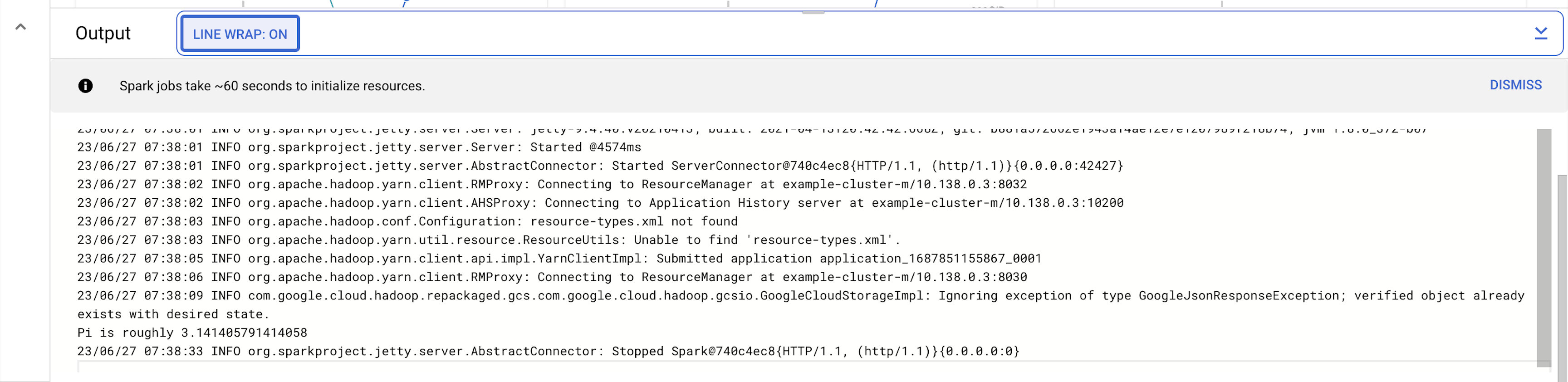
Your job has successfully calculated a rough value for pi!
Task 4. Update a cluster to modify the number of workers
To change the number of worker instances in your cluster:
Select Clusters in the left navigation pane to return to the Dataproc Clusters view.
Click example-cluster in the Clusters list. By default, the page displays an overview of your cluster's CPU usage.
Click Configuration to display your cluster's current settings.
Click Edit. The number of worker nodes is now editable.
Enter 4 in the Worker nodes field.
Click Save.
Your cluster is now updated. Check out the number of VM instances in the cluster.
Answer
gcloud dataproc clusters update example-cluster \
--num-workers=4 \
--region=$REGION