ETL Processing on Google Cloud Using Dataflow and BigQuery (Python) - GSP290
A passionate full-stack developer from @ePlus.DEV
Overview
In Google Cloud, you can build data pipelines that execute Python code to ingest and transform data from publicly available datasets into BigQuery using these Google Cloud services:
Cloud Storage
Dataflow
BigQuery
In this lab, you use these services to create your own data pipeline, including the design considerations and implementation details, to ensure that your prototype meets the requirements. Be sure to open the Python files and read the comments when instructed.
What you'll do
In this lab, you learn how to:
Build and run Dataflow pipelines (Python) for data ingestion
Build and run Dataflow pipelines (Python) for data transformation and enrichment
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
Note: Use an Incognito or private browser window to run this lab. This prevents any conflicts between your personal account and the Student account, which may cause extra charges incurred to your personal account.
- Time to complete the lab---remember, once you start, you cannot pause a lab.
Note: If you already have your own personal Google Cloud account or project, do not use it for this lab to avoid extra charges to your account.
How to start your lab and sign in to the Google Cloud console
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
The Open Google Cloud console button
Time remaining
The temporary credentials that you must use for this lab
Other information, if needed, to step through this lab
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account.
If necessary, copy the Username below and paste it into the Sign in dialog.
student-04-c53c39caeba6@qwiklabs.netYou can also find the Username in the Lab Details panel.
Click Next.
Copy the Password below and paste it into the Welcome dialog.
bGDAuTj83DU3You can also find the Password in the Lab Details panel.
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials.
Note: Using your own Google Cloud account for this lab may incur extra charges.
Click through the subsequent pages:
Accept the terms and conditions.
Do not add recovery options or two-factor authentication (because this is a temporary account).
Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.
Note: To view a menu with a list of Google Cloud products and services, click the Navigation menu at the top-left.

Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
Click Activate Cloud Shell
at the top of the Google Cloud console.

When you are connected, you are already authenticated, and the project is set to your Project_ID, qwiklabs-gcp-03-396804febdfd. The output contains a line that declares the Project_ID for this session:
Your Cloud Platform project in this session is set to qwiklabs-gcp-03-396804febdfd
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
- (Optional) You can list the active account name with this command:
gcloud auth list
- Click Authorize.
Output:
ACTIVE: *
ACCOUNT: student-04-c53c39caeba6@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Optional) You can list the project ID with this command:
gcloud config list project
Output:
[core]
project = qwiklabs-gcp-03-396804febdfd
Note: For full documentation of gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
Task 1. Ensure that the Dataflow API is successfully enabled
To ensure access to the necessary API, restart the connection to the Dataflow API.
Important: even if the API is already enabled, follow steps 1-4 below to disable, and then reenable the API, in order to restart the API successfully.
In the Cloud Console, enter "Dataflow API" in the top search bar. Click on the result for Dataflow API.
Click Manage.
Click Disable API.
If asked to confirm, click Disable.
- Click Enable.
When the API has been enabled again, the page will show the option to disable.
Test completed task
Click Check my progress to verify your performed task.
Disable and re-enable the Dataflow API
Check my progress
Task 2. Download the starter code
- Run the following command in the Cloud Shell to get Dataflow Python Examples from Google Cloud's professional services GitHub:
gsutil -m cp -R gs://spls/gsp290/dataflow-python-examples .
- Now, in Cloud Shell, set a variable equal to your project id.
export PROJECT=qwiklabs-gcp-03-396804febdfd
gcloud config set project $PROJECT
Task 3. Create a Cloud Storage bucket
- Use the make bucket command in the Cloud Shell to create a new regional bucket in the
us-central1region within your project:
gsutil mb -c regional -l us-central1 gs://$PROJECT
Test completed task
Click Check my progress to verify your performed task.
Create a Cloud Storage Bucket
Check my progress
Task 4. Copy files to your bucket
- Use the
gsutilcommand in the Cloud Shell to copy files into the Cloud Storage bucket you just created:
gsutil cp gs://spls/gsp290/data_files/usa_names.csv gs://$PROJECT/data_files/
gsutil cp gs://spls/gsp290/data_files/head_usa_names.csv gs://$PROJECT/data_files/
Test completed task
Click Check my progress to verify your performed task.
Copy Files to Your Bucket
Check my progress
Task 5. Create a BigQuery dataset
- In the Cloud Shell, create a dataset in BigQuery Dataset called
lake. This is where all of your tables will be loaded in BigQuery:
bq mk lake
Test completed task
Click Check my progress to verify your performed task.
Create the BigQuery Dataset (name: lake)
Check my progress
Task 6. Build a Dataflow pipeline
In this section you will create an append-only Dataflow which will ingest data into the BigQuery table. You can use the built-in code editor which will allow you to view and edit the code in the Google Cloud console.
Open the Cloud Shell Code Editor
- Navigate to the source code by clicking on the Open Editor icon in the Cloud Shell:

- If prompted, click on Open in a New Window. It will open the code editor in new window. The Cloud Shell Editor allows you to edit files in the Cloud Shell environment, from the Editor you can return to the Cloud Shell by Clicking on Open Terminal.
Task 7. Data ingestion with a Dataflow Pipeline
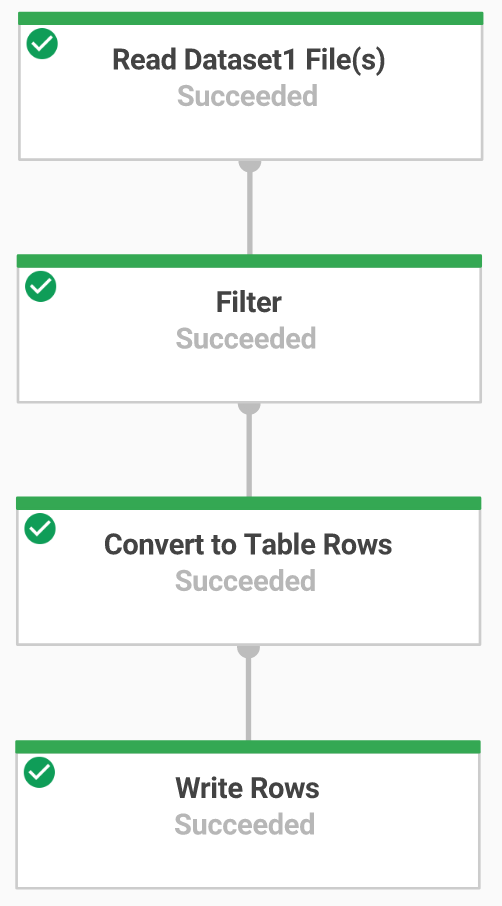
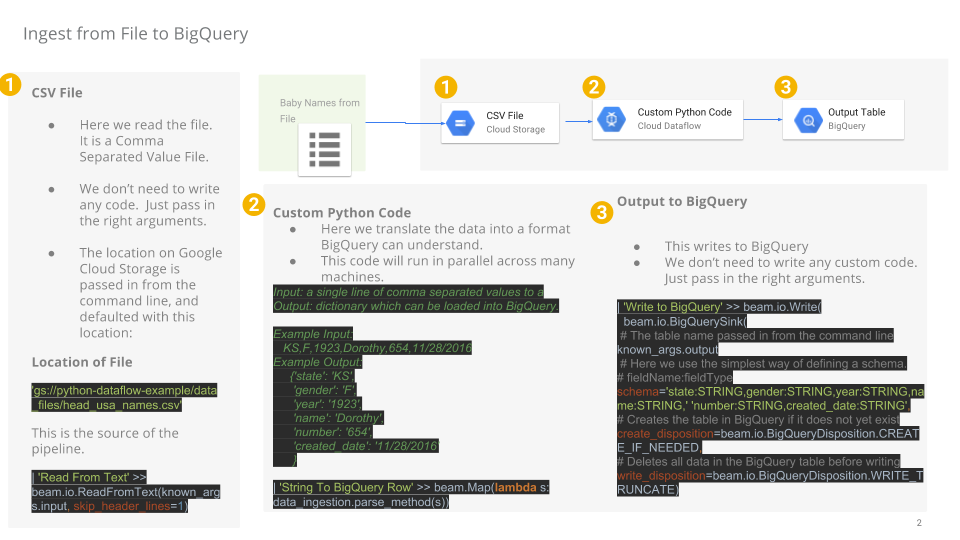
You will now build a Dataflow pipeline with a TextIO source and a BigQueryIO destination to ingest data into BigQuery. More specifically, it will:
Ingest the files from Cloud Storage.
Filter out the header row in the files.
Convert the lines read to dictionary objects.
Output the rows to BigQuery.
Task 8. Review pipeline Python code
In the Code Editor navigate to dataflow-python-examples > dataflow_python_examples and open the data_ingestion.py file. Read through the comments in the file, which explain what the code is doing. This code will populate the dataset lake with a table in BigQuery.
Task 9. Run the Apache Beam pipeline
- Return to your Cloud Shell session for this step. You will now do a bit of set up for the required python libraries.
The Dataflow job in this lab requires Python3.8. To ensure you're on the proper version, you will run the Dataflow processes in a Python 3.8 Docker container.
- Run the following in Cloud Shell to start up a Python Container:
docker run -it -e PROJECT=$PROJECT -v $(pwd)/dataflow-python-examples:/dataflow python:3.8 /bin/bash
This command will pull a Docker container with the latest stable version of Python 3.8 and execute a command shell to run the next commands within the container. The -v flag provides the source code as a volume for the container so that we can edit in Cloud Shell editor and still access it within the running container.
- Once the container finishes pulling, and starts executing in the Cloud Shell, run the following to install
apache-beamin that running container:
pip install apache-beam[gcp]==2.24.0
- Next, in the running container in the Cloud Shell, change directories into where you linked the source code:
cd dataflow/
Run the ingestion Dataflow pipeline in the cloud
- The following will spin up the workers required, and shut them down when complete:
python dataflow_python_examples/data_ingestion.py \
--project=$PROJECT --region=us-central1 \
--runner=DataflowRunner \
--machine_type=e2-standard-2 \
--staging_location=gs://$PROJECT/test \
--temp_location gs://$PROJECT/test \
--input gs://$PROJECT/data_files/head_usa_names.csv \
--save_main_session
- Return to the Cloud Console and open the Navigation menu > Dataflow to view the status of your job.

Click on the name of your job to watch it's progress. Once your Job Status is Succeeded, you can move to the next step. This Dataflow pipeline will take approximately five minutes to start, complete the work, and then shutdown.
Navigate to BigQuery (Navigation menu > BigQuery) see that your data has been populated.
- Click on your project name to see the usa_names table under the
lakedataset.

- Click on the table then navigate to the Preview tab to see examples of the
usa_namesdata.
Note: If you don't see the usa_names table, try refreshing the page or view the tables using the classic BigQuery UI.
Test completed task
Click Check my progress to verify your performed task.
Build a Data Ingestion Dataflow Pipeline
Check my progress
Task 10. Data transformation
You will now build a Dataflow pipeline with a TextIO source and a BigQueryIO destination to ingest data into BigQuery. More specifically, you will:
Ingest the files from Cloud Storage.
Convert the lines read to dictionary objects.
Transform the data which contains the year to a format BigQuery understands as a date.
Output the rows to BigQuery.
Review transformation pipeline python code
In the Code Editor, open data_transformation.py file. Read through the comments in the file which explain what the code is doing.
Task 11. Run the Dataflow transformation pipeline
You will run the Dataflow pipeline in the cloud. This will spin up the workers required, and shut them down when complete.
- Run the following commands to do so:
python dataflow_python_examples/data_transformation.py \
--project=$PROJECT \
--region=us-central1 \
--runner=DataflowRunner \
--machine_type=e2-standard-2 \
--staging_location=gs://$PROJECT/test \
--temp_location gs://$PROJECT/test \
--input gs://$PROJECT/data_files/head_usa_names.csv \
--save_main_session
Navigate to Navigation menu > Dataflow and click on the name of this job to view the status of your job. This Dataflow pipeline will take approximately five minutes to start, complete the work, and then shutdown.
When your Job Status is Succeeded in the Dataflow Job Status screen, navigate to BigQuery to check to see that your data has been populated.
You should see the usa_names_transformed table under the
lakedataset.Click on the table and navigate to the Preview tab to see examples of the
usa_names_transformeddata.
Note: If you don't see the usa_names_transformed table, try refreshing the page or view the tables using the classic BigQuery UI.
Test completed task
Click Check my progress to verify your performed task.
Build a Data Transformation Dataflow Pipeline
Check my progress
Task 12. Data enrichment
You will now build a Dataflow pipeline with a TextIO source and a BigQueryIO destination to ingest data into BigQuery. More specifically, you will:
Ingest the files from Cloud Storage.
Filter out the header row in the files.
Convert the lines read to dictionary objects.
Output the rows to BigQuery.
Task 13. Review data enrichment pipeline ython code
In the Code Editor, open
data_enrichment.pyfile.Check out the comments which explain what the code is doing. This code will populate the data in BigQuery.
Line 83 currently looks like:
values = [x.decode('utf8') for x in csv_row]
- Edit it to look like the following:
values = [x for x in csv_row]
- When you have finished editing this line, remember to Save this updated file by selecting the File pull down in the Editor and clicking on Save
Task 14. Run the Data Enrichment Dataflow pipeline
Here you'll run the Dataflow pipeline in the cloud.
- Run the following in the Cloud Shell to spin up the workers required, and shut them down when complete:
python dataflow_python_examples/data_enrichment.py \
--project=$PROJECT \
--region=us-central1 \
--runner=DataflowRunner \
--machine_type=e2-standard-2 \
--staging_location=gs://$PROJECT/test \
--temp_location gs://$PROJECT/test \
--input gs://$PROJECT/data_files/head_usa_names.csv \
--save_main_session
Navigate to Navigation menu > Dataflow to view the status of your job. This Dataflow pipeline will take approximately five minutes to start, complete the work, and then shutdown.
Once your Job Status is Succeed in the Dataflow Job Status screen, navigate to BigQuery to check to see that your data has been populated.
You should see the usa_names_enriched table under the lake dataset.
- Click on the table and navigate to the Preview tab to see examples of the
usa_names_enricheddata.
Note: If you don't see the usa_names_enriched table, try refreshing the page or view the tables using the classic BigQuery UI.
Test the completed data enrichment task
Click Check my progress to verify your performed task.
Build a Data Enrichment Dataflow Pipeline
Check my progress
Task 15. Data lake to Mart and Review pipeline python code
Now build a Dataflow pipeline that reads data from two BigQuery data sources, and then joins the data sources. Specifically, you:
Ingest files from two BigQuery sources.
Join the two data sources.
Filter out the header row in the files.
Convert the lines read to dictionary objects.
Output the rows to BigQuery.
In the Code Editor, open data_lake_to_mart.py file. Read through the comments in the file which explain what the code is doing. This code will join two tables and populate the resulting data in BigQuery.
Task 16. Run the Apache Beam Pipeline to perform the Data Join and create the resulting table in BigQuery
Now run the Dataflow pipeline in the cloud.
- Run the following code block, in the Cloud Shell, to spin up the workers required, and shut them down when complete:
python dataflow_python_examples/data_lake_to_mart.py \
--worker_disk_type="compute.googleapis.com/projects//zones//diskTypes/pd-ssd" \
--max_num_workers=4 \
--project=$PROJECT \
--runner=DataflowRunner \
--machine_type=e2-standard-2 \
--staging_location=gs://$PROJECT/test \
--temp_location gs://$PROJECT/test \
--save_main_session \
--region=us-central1
Navigate to Navigation menu > Dataflow and click on the name of this new job to view the status. This Dataflow pipeline will take approximately five minutes to start, complete the work, and then shutdown.
Once your Job Status is Succeeded in the Dataflow Job Status screen, navigate to BigQuery to check to see that your data has been populated.
You should see the orders_denormalized_sideinput table under the lake dataset.
- Click on the table and navigate to the Preview section to see examples of
orders_denormalized_sideinputdata.
Note: If you don't see the orders_denormalized_sideinput table, try refreshing the page or view the tables using the classic BigQuery UI.
Test completed JOIN task
Click Check my progress to verify your performed task.
Build a Data lake to Mart Dataflow Pipeline
Check my progress
Test your understanding
Below are multiple choice questions to reinforce your understanding of this lab's concepts. Answer them to the best of your abilities.
ETL stands for ____.
Extract, Transform and Load
Electronic Transferable Ledger
Solution of Lab
export REGION=

curl -LO raw.githubusercontent.com/quiccklabs/Labs_solutions/master/ETL%20Processing%20on%20Google%20Cloud%20Using%20Dataflow%20and%20BigQuery%20Python/quicklabgsp290.sh
sudo chmod +x quicklabgsp290.sh
./quicklabgsp290.sh