Exploring Dataset Metadata Between Projects with Data Catalog - GSP789
A passionate full-stack developer from @ePlus.DEV
Overview
Data Catalog is a fully managed, scalable metadata management service within Dataplex.
Managing data assets can be time consuming and expensive without the right tools. Data Catalog provides a centralized place where organizations can find, curate and describe their data assets.
Using Data Catalog
There are two main ways you interact with Data Catalog:
Searching for data assets that you have access to
Tagging assets with metadata
What you'll learn
In this lab, you learn how to:
Explore a simulated enterprise environment of 2 projects, 2 datasets, and 2 user accounts.
Navigate through a BigQuery table manually in the UI.
Run queries to better understand sensitive data columns to then tag later.
Use Data Catalog to search for existing datasets across projects.
Use Data Catalog tag templates to tag assets with rich metadata.
Why is this useful?
View data assets across multiple projects in your organization.
Create re-usable tag templates to add rich data descriptions for your teams.
Quickly highlight which datasets have PII (Personally Identifiable Information).
Metadata Access control is inherited based on logged in users (no separate Data Catalog ACLs needed).
Prerequisites
Very Important: Before starting this lab, log out of your personal or corporate gmail account, or run this lab in Incognito. This prevents sign-in confusion while the lab is running.
Setup and requirements
If you have not done so already, click Start Lab.
Tip: It will take 3 - 5 minutes for the lab environment to auto-generate 2 Google Cloud Projects, 2 pre-populated Datasets, and 2 user accounts. You do not need to wait for the lab resources to complete to continue reading this lab (you won't be logging in under after you read the scenario below)
Click Open Bike Console in the lab or in a new Incognito Browser window, navigate to the Cloud Console. Do not log in with any of the accounts provided yet. Continue reading the scenario first and you will be instructed later which account to use.
Important Note: Once started your lab cannot be paused and ending your lab will delete all student projects that are still running.
Scenario: CEO of NYC transportation company
You are the head of a transportation business operating in New York City. You have teams of data analysts that query datasets you have collected about NYC travel (by bike and car).
Challenges:
Some of your datasets contain sensitive information that you want to access control.
Your team complains that finding the right dataset is difficult among the many other datasets they have access to.
To comply with recent regulatory requirements, you need a very clear way to flag which datasets have PII (Personally Identifiable Information) in them.
Datasets for your organization
NYC Bike Share Trips
NYC Motor Vehicle Collisions
Each data engineering team maintains their dataset in their own separate Google Cloud Project so they can better manage access and billing. While this is good for them, it makes these datasets less discoverable for your team of analysts.
Not all analyst roles are equal
To make matters more complex, you have different levels of data analysts on your BI team working for you:
Data Analysts - least privileges
Owner - full admin
Review what is being automatically created for you
In order to best simulate a true enterprise environment with multiple projects and datasets to catalog, your engineering team has given you access to already existing resources (the lab preloads resources so you don't have to create them).
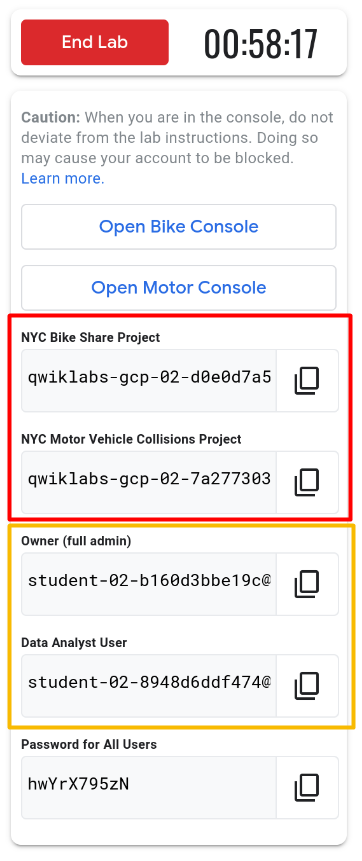
Your team has provided you logins as shown above to:
2 Projects
2 User Accounts
They added the following notes on access restriction:
Owner should have full access to all projects and datasets.
Data Analysts should not have access to see or query the NYC Motor Vehicle Collisions dataset (sensitive data).
Part 1: Explore the existing data environment with the owner role
Recall that your data engineering team provided you with three projects each containing a different New York City dataset. Confirm the Owner role can see and query all datasets.
Log in using the Owner (full admin) auto-generated email and password provided as part of this lab.
Accept the Terms and Conditions to use Google Cloud (if prompted).
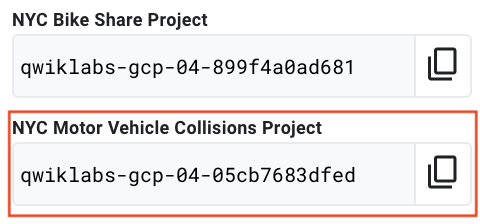
Find the NYC Collisions project
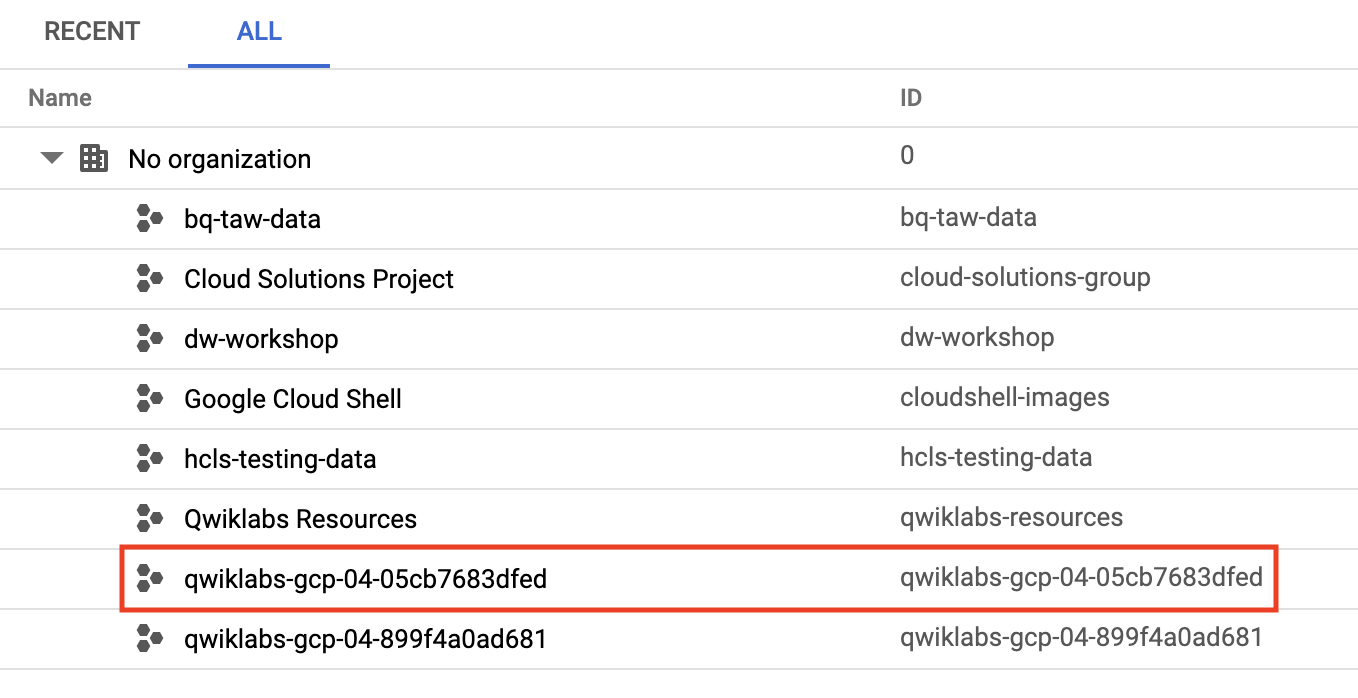
- Click your project name dropdown at the top of the page to Select a Project.

- Refer to the Qwiklabs auto-generated project name for
NYC Motor Vehicle Collisions Projectand find that string value in the Select a Project popup:
Enable the Data Catalog API
Use the Navigation menu > Solutions > All products to scroll down until you see Data Catalog.
Hover over the name, then click the pin icon. This moves Data Catalog to the top of the Navigation menu.
Click Data Catalog. If a pop-up appears, click Close.
Confirm the API is enabled already (if there is no prompt to enable the API, then it is already enabled and no action is needed.)
You return later in this lab to use Data Catalog after you manually search and query the datasets first in BigQuery.
Navigate to and pin BigQuery
Use the Navigation menu scroll down until you see BigQuery.
Hover over the name and click the pin icon.
Click BigQuery then click Done.
Task 1. Confirm the owner role can view and query the new_york_mv_collisions Dataset
Confirm that the owner role can view the new_york_mv_collisions dataset.
In BigQuery, under Explorer click your project name to toggle open the available datasets you have access to see.
Confirm you can see the
new_york_mv_collisionsdataset.Click the
new_york_mv_collisionsdataset to toggle open the tables inside.Click the
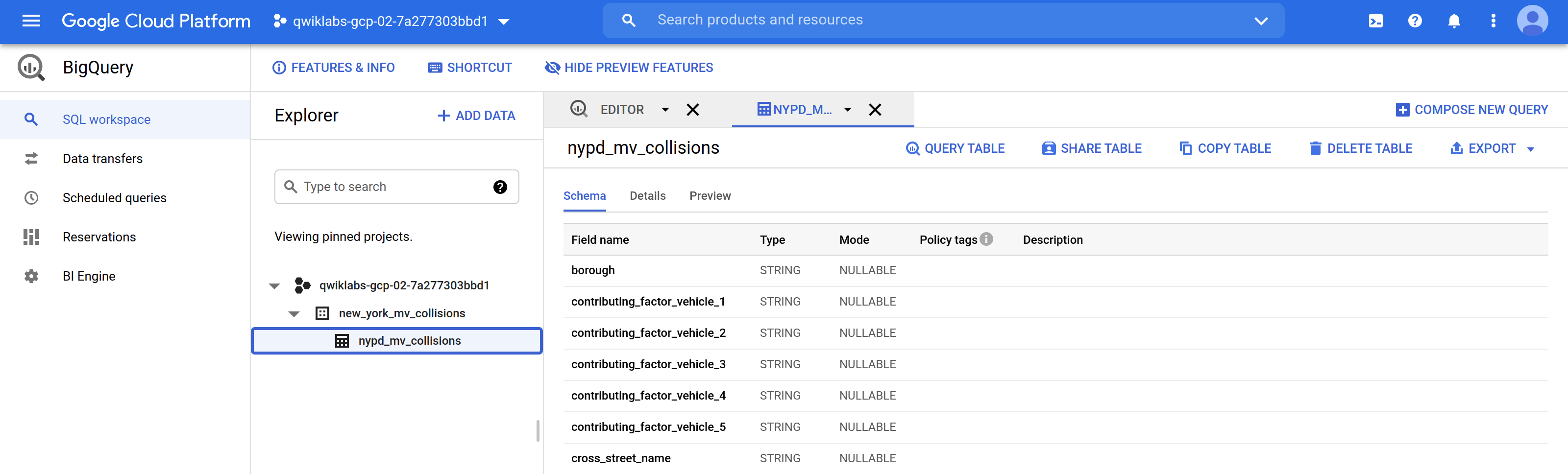
nypd_mv_collisionstable and explore the available fields in the schema.
The schema should look similar to the below:
Answer the following questions.
Which BigQuery UI tab will show you the data types?DetailsPreviewSchema
Submit
Using the Details tab, how many records are in this table?Less than 500,0001.6+ Million1 Million
Submit
Using the Schema tab, which fields could be sensitive and need to be handled with care?number_of_persons_killedon_street_namelocationAll of the Above
Submit
While there isn't personally identifiable information like a phone number or email address in this table, you still need to use caution when sharing this dataset across the wider team.
What could be a solution for addressing privacy and sensitivity concerns?Control access at the project and role levelFind a way to tag the dataset / columns as sensitiveControl access at the column levelAll of the Above
Submit
The remainder of this lab will focus on teaching you ways to access restricted datasets and use Data Catalog to proactively tag datasets and tables with rich metadata for your organization.
Note: This NYPD Collisions dataset is auto-loaded into your project from the original BigQuery Public Dataset which is updated daily. Click the link to learn more about how the dataset was collected and to see example queries.
Confirm that the owner role can query the collisions dataset
Since you're logged in as a global owner, confirm you can see and access both projects and datasets. Confirm you can run the below query.
- Copy and paste the below query into the BigQuery Query Editor and click Run:
What were the 10 most common factors in NYC car crashes?
SELECT
contributing_factor_vehicle_1 AS collision_factor,
COUNT(*) AS num_collisions
FROM
`new_york_mv_collisions.nypd_mv_collisions`
WHERE
contributing_factor_vehicle_1 != "Unspecified"
AND contributing_factor_vehicle_1 != ""
GROUP BY
collision_factor
ORDER BY
num_collisions DESC
LIMIT 10;
What was the most common factor?Failure to Yield Right-of-WayFatigued/DrowsyDriver Inattention/Distraction
Submit
Click Check my progress to verify the objective.
Query the NYC collision data
Check my progress
Task 2. Confirm the owner role can view and query the Bike Share dataset
Click Select a Project at the top of the page.
Click the All tab.
Find the Bike Share dataset by referring to the correct auto-generated project-id:
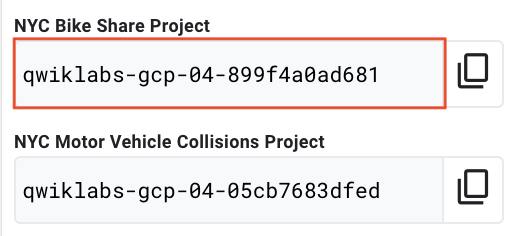
- Click the project ID.
Note: If prompted, Click LEAVE for Unsaved work.
- In the BigQuery UI, toggle open the Project ID >
new_york_citibike>citibike_tripstable.
When viewing the schema, details, and preview answer the below questions.
How many records are in the table citibike_trips table? Choose the best answerOver 210 Million TripsOver 58 Million TripsLess than 1 Million Trips
Submit
What are the most popular Bike Share routes by gender?
The NYC Citi Bike Public Dataset tracks each individual bike share trip (starting location, ending location) as well as other fields for each user.
- Add the below query to the Query editor and Run it to see the most popular routes by gender. Note that the only three values provided in the dataset are unknown, male, and female which may not be representative of all the gender values for bike share riders:
WITH unknown AS (
SELECT
gender,
CONCAT(start_station_name, " to ", end_station_name) AS route,
COUNT(*) AS num_trips
FROM
`new_york_citibike.citibike_trips`
WHERE gender = 'unknown'
GROUP BY
gender,
start_station_name,
end_station_name
ORDER BY
num_trips DESC
LIMIT 5
)
, female AS (
SELECT
gender,
CONCAT(start_station_name, " to ", end_station_name) AS route,
COUNT(*) AS num_trips
FROM
`new_york_citibike.citibike_trips`
WHERE gender = 'female'
GROUP BY
gender,
start_station_name,
end_station_name
ORDER BY
num_trips DESC
LIMIT 5
)
, male AS (
SELECT
gender,
CONCAT(start_station_name, " to ", end_station_name) AS route,
COUNT(*) AS num_trips
FROM
`bigquery-public-data.new_york_citibike.citibike_trips`
WHERE gender = 'male'
GROUP BY
gender,
start_station_name,
end_station_name
ORDER BY
num_trips DESC
LIMIT 5
)
SELECT * FROM unknown
UNION ALL
SELECT * FROM female
UNION ALL
SELECT * FROM male;
TRUE or FALSE: The most popular route for males is the same as the most popular route for femalesTrueFalse
Submit
Looking at the citibike_trips table schema, which fields will you want to tag as sensitive?birth_yeargendercustomer_planAll of the Above
Submit
Click Check my progress to verify the objective.
Query the most popular bike route by gender
Check my progress
You explore how to tag datasets and tables with sensitive data next.
Exploration recap
You have explored each NYC dataset (Collisions and Bike Share trips)
Each dataset is stored in a separate project
The Owner role (who you are logged in as now) has access to view and query each dataset
Part 2: Explore the existing data environment with restricted user access
So far in the lab you have been logged in as the Owner account which your data engineering team has provided with the highest level permissions.
You have asked your engineering teams to limit access to your Data Analyst users as follows
Data Analysts should see:
- NYC Bike Share
Data Analysts should NOT see:
- NYC Motor Vehicle Collisions
Sign out of the Owner account
Click the profile icon.
Sign out.
Task 3. Log in with the Data Analyst user and confirm restricted project access
Click Use another account.
Log back into Google Cloud using the
Data Analyst Useremail and shared password.Under select a project confirm you are only able to see one and not two Qwiklabs auto-generated projects.
Select the Qwiklabs project you can access.
Navigate to BigQuery.
Task 4. Attempt to directly query a private dataset
In BigQuery, even if a project is not pinned or visible in your Explorer section you can still query it if you have access. Try to query the NYC Collisions dataset directly as a Data Analyst user by using the project-id.
- Add the below query from before and replace the project id prefix the project id for the
NYC Motor Vehicle Collisions Project:
SELECT
contributing_factor_vehicle_1 AS collision_factor,
COUNT(*) AS num_collisions
FROM
`qwiklabs-gcp-REPLACE-HERE.new_york_mv_collisions.nypd_mv_collisions`
WHERE
contributing_factor_vehicle_1 != "Unspecified"
AND contributing_factor_vehicle_1 != ""
GROUP BY
collision_factor
ORDER BY
num_collisions DESC
LIMIT 10;
Receiving an access denied error message verifies your Data Analyst access level.
You have now explored the different privileges and accesses granted to owner roles (broadest set of privileges) and Data Analysts (most restrictive) when it comes to accessing projects, datasets, and queries.
Next you try and find a hidden dataset using the Data Catalog search functionality. Do you think it will show up for Data Analysts if BigQuery blocks you?
Part 3: Using Data Catalog to tag datasets across projects
Now that you are familiar with the datasets and access levels granted to different roles, you address the challenges posed earlier in the sample scenario:
Challenges:
Some of your datasets contain sensitive information that you want to access control.
Your team complains that finding the right dataset is difficult among the many other datasets they have access to.
To comply with recent regulatory requirements, you need a very clear way to flag which datasets have PII (Personally Identifiable Information) in them. You address these challenges and complete this task with the Data Catalog service.
- Open the navigation menu and click on Data Catalog.
Note: If prompted, Click LEAVE for Unsaved work.
Note: If you are presented with a screen asking you to enable the API, you need to re-login with the Owner role and enable it (this was a step earlier in this lab.)
- On the Data Catalog homepage under Systems, filter for BigQuery.
Note: You may also see rows for the qwiklabs-resources project which you can ignore. That project provides shared assets across all labs.
Enter
qwiklabs-gcpinto Data Catalog's search bar to filter out external Qwiklabs resources.Confirm your view as a Data Analyst looks similar to below:
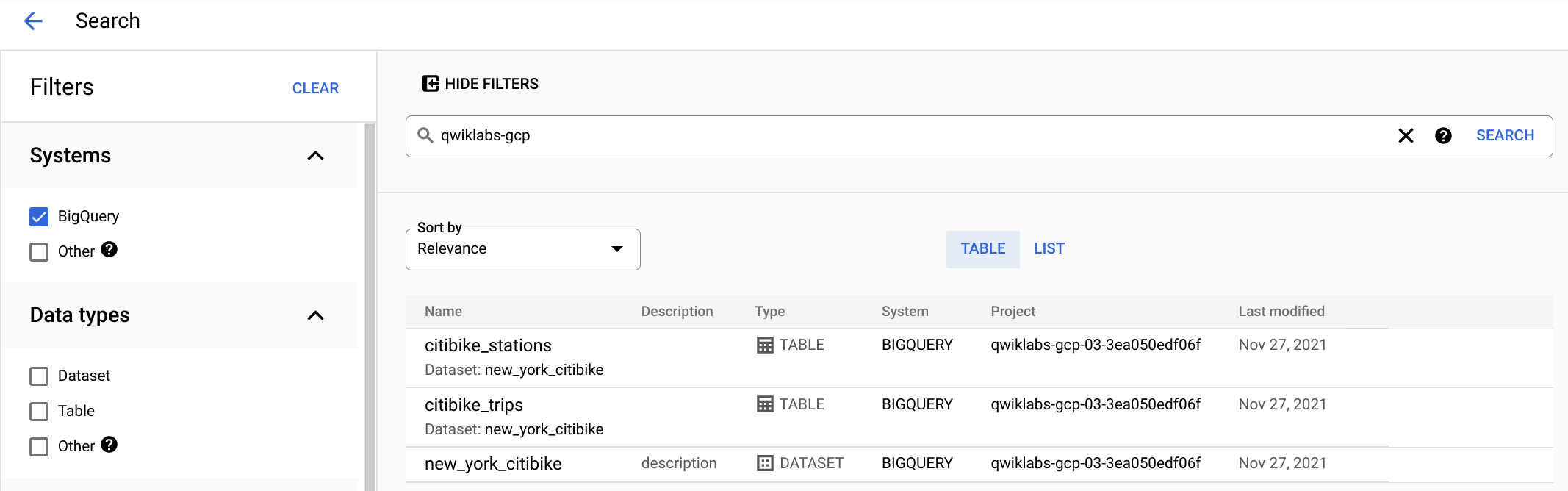
True or false: Data Catalog can only surface BigQuery metadata and tags and not other data systems like Pub/SubTrueFalse
Regardless of the project you are logged into, Data Catalog will surface ALL of the BigQuery datasets that your role has access to.
Refer to the Type column. Which Datasets can you see in the Data Catalog search as a Data Analyst user?taxinonenew_york_citibikenew_york_mv_collisions
Submit
As a Data Analyst user, you do not see new_york_mv_collisions in Data Catalog even though it does exist (you query it as an Owner).
Why is that? Next, explore how access control works at the Data Catalog level.
How Data Catalog surfaces metadata
Before searching, discovering, or displaying Google Cloud resources, Data Catalog checks that the user has been granted an IAM role with the metadata read permissions required by BigQuery, Pub/Sub, or other source system to access the resource.
Example: Data Catalog checks that the user has been granted a role with bigquery.tables.get permission before displaying BigQuery table metadata.
True or false: Google Cloud project owners have to maintain a separate access control list for BigQuery metadata in Data Catalog and cannot pass through existing BigQuery permissions for a given user.TrueFalse
Task 5. Create a Data Catalog tag template from a BigQuery dataset
- Click on the
new_york_citibikedataset entry. This is a subset of the ride share dataset you are allowed to view.
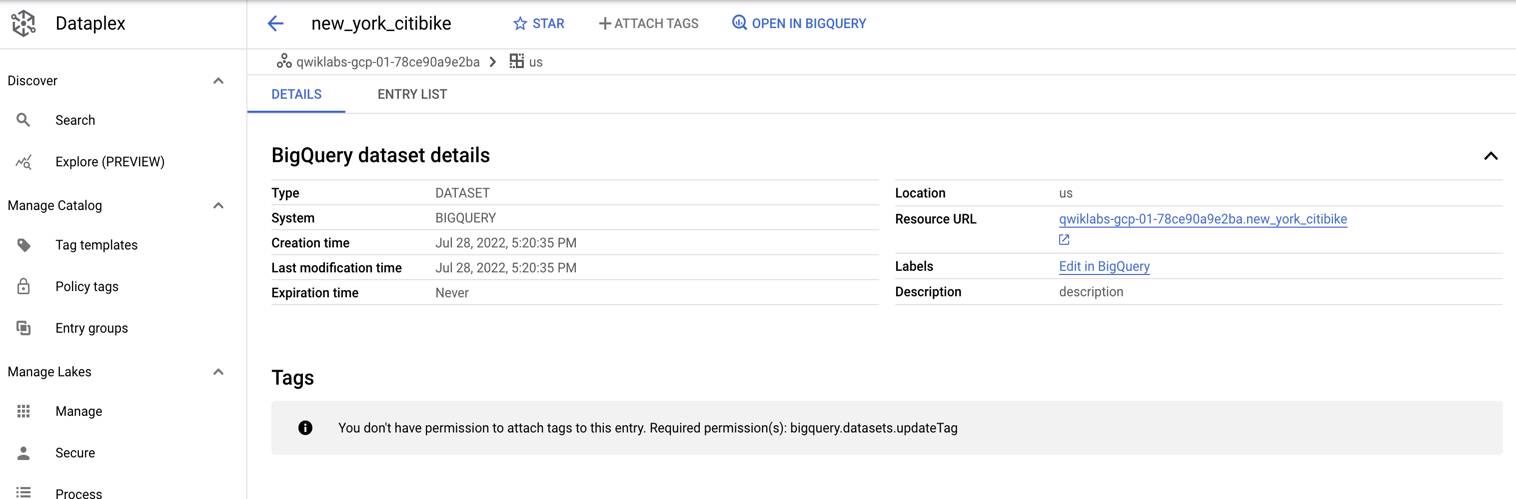
For BigQuery tables, Data Catalog allows you to tag:
The Dataset itself
The table
Individual columns
Attempt to click on the Attach tag button.
Confirm you get a similar error:
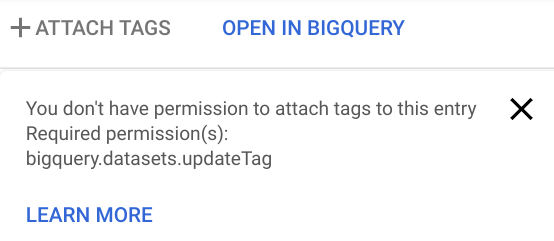
- In that dialog, hover over Learn more to see why it is not available.
It appears the Data Analyst role can search for metadata in Data Catalog but not attach new tags.
Next you'll see how Data Catalog tagging permissions and tag templates work.
Data Catalog templates, tags, and permissions
Data Catalog tag templates help you create and manage common metadata about data assets in a single location. The tags are attached to the data asset, which means it can be discovered in the Data Catalog system. Using this feature, you can also build additional applications that consume this contextual metadata about a data asset.
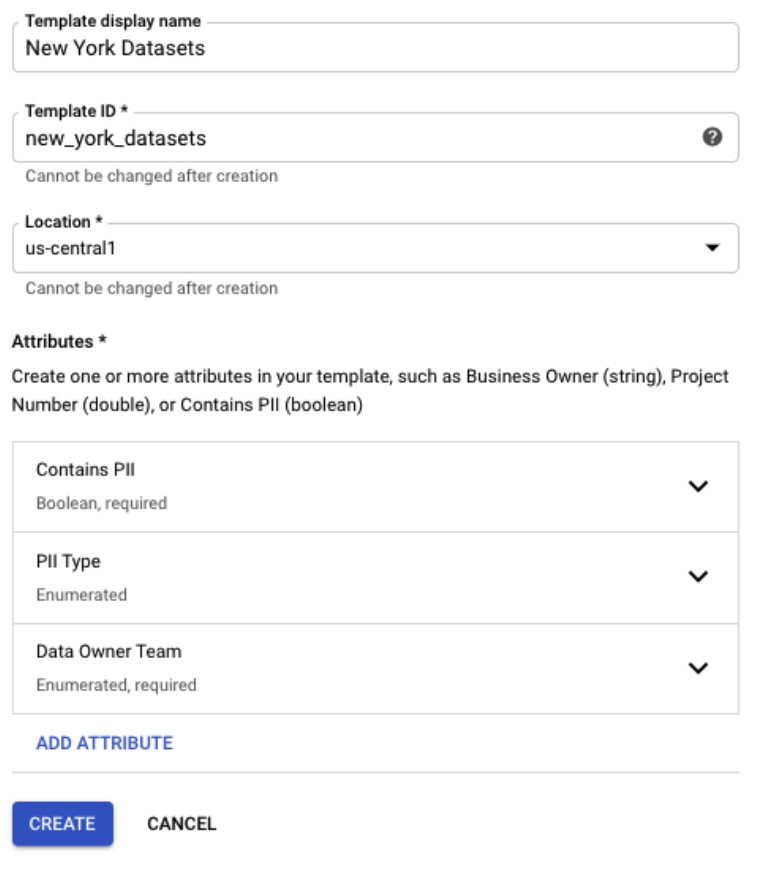
What does a tag template look like?
Who can create a tag template?
In order to create tag templates, the user needs to have, at minimum, edit access to the resource in question (BigQuery for this lab) AND datacatalog.tagTemplateUser (assuming a template has already been created). To learn more, refer to the Data Catalog IAM Guide.
What if you need to create a new tag template? Then you would need to be at minimum a datacatalog.tagTemplateCreator or roles/datacatalog.tagTemplateOwner. Owner allows you to delete existing templates and additional admin privileges.
Most common Data Catalog predefined Cloud IAM roles:
roles/datacatalog.tagTemplateViewerroles/datacatalog.tagTemplateUserroles/datacatalog.tagTemplateCreatorroles/datacatalog.tagTemplateOwnerFor a complete list of roles, refer to Data Catalog roles
Task 6. Create a new Data Catalog template
Log in as the Owner role which has the
roles/datacatalog.tagTemplateOwnerpermission.Select the
NYC Bike Share Projectthat you were using before.
Note: If you see a permission error, re-log with correct credentials. You probably picked the wrong Owner.
In the Google Cloud Console, in the Navigation menu (), click View all products. Under Analytics, click Dataplex Universal Catalog.
On the left menu, under Manage Metadata, click Catalog.
Click Create tag template (Deprecated).
When prompted Are you sure you want to continue?, click Proceed.
Note: Tag templates are being replaced by aspect types but are still functional at this time. You can proceed with the next steps to create a tag template.
- Enter the required information to define the tag template:
| Property | Value |
| Template Display Name | New York Datasets |
| Template ID | Leave the default value. |
| Location | us-central1 |
| Visibility | Public |
Click Add Field
Name the new field Contains PII, check Make this field required, and select the Boolean type. Then, click Done when you're finished.
Click Add field.
Name the field PII Type, select the Enumerated type, and add the following values. Then, click Done when you're finished:
Value 1: None
Value 2: Birth date
Value 3: Gender
Value 4: Geo location
Click Add field.
Name the field Data Owner Team, check Make this field required, select the Enumerated type, and add the following values. Then, click Done when you're finished:
Value 1: Marketing
Value 2: Data Science
Value 3: Sales
Value 4: Engineering
- Click Create.
Applying tags at the dataset level
Click on Search for entries not using this template.
Click on the new_york_mv_collisions dataset.
Notice that there are no tags below the dataset name.
Click Attach Tags.
Choose the template that you created earlier then click OK.
Use the dropdown menu to populate values for template fields with the following, then click Save:
Contains PII: True
PII Type: Geo location
Data Owner Team: Engineering
- View the tags at the dataset level.
Applying tags at the table and column level
For more granular asset tagging, you can apply tags at the table and column level.
Navigate back to the assets from our earlier search and click on the table
nypd_mv_collisions.Click Attach Tags and set the following fields for:
Table: nypd_mv_collisions
Column: location
Tag Template: New York Datasets
Tag values:
Contains PII: True
PII Type: Geo location
Data Owner Team: Engineering
- Click Save.
Note that the table now has three tag values: one each for Contains PII, PII Type, and Data Owner Team.
Click Check my progress to verify the objective.
Creating a Data Catalog tag template
Check my progress
Searching datasets by tag and tag key
Now that you have tagged, you can search your catalog by the tags you just added.
- In the search bar, copy and paste
tag:YOUR-PROJECT-ID-HERE.new_york_datasets.contains_pii, and replaceYOUR-PROJECT-ID-HEREwith your current Project ID.
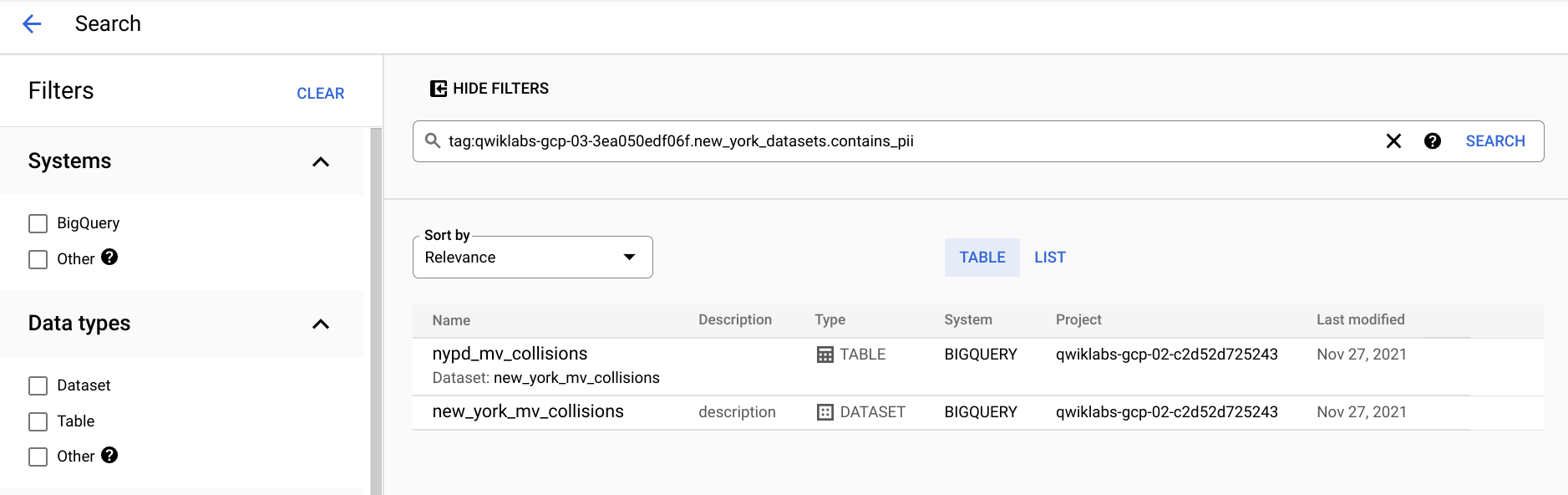
For other examples of how to quickly search across your catalog, refer to Search and view data assets with Data Catalog.
Solution of Lab
curl -LO https://github.com/ArcadeCrew/Google-Cloud-Labs/raw/refs/heads/main/Exploring%20Dataset%20Metadata%20Between%20Projects%20with%20Data%20Catalog/arcadecrew.sh
sudo chmod +x arcadecrew.sh
./arcadecrew.sh