Intro to Hadoop - Big Data
A passionate full-stack developer from @ePlus.DEV
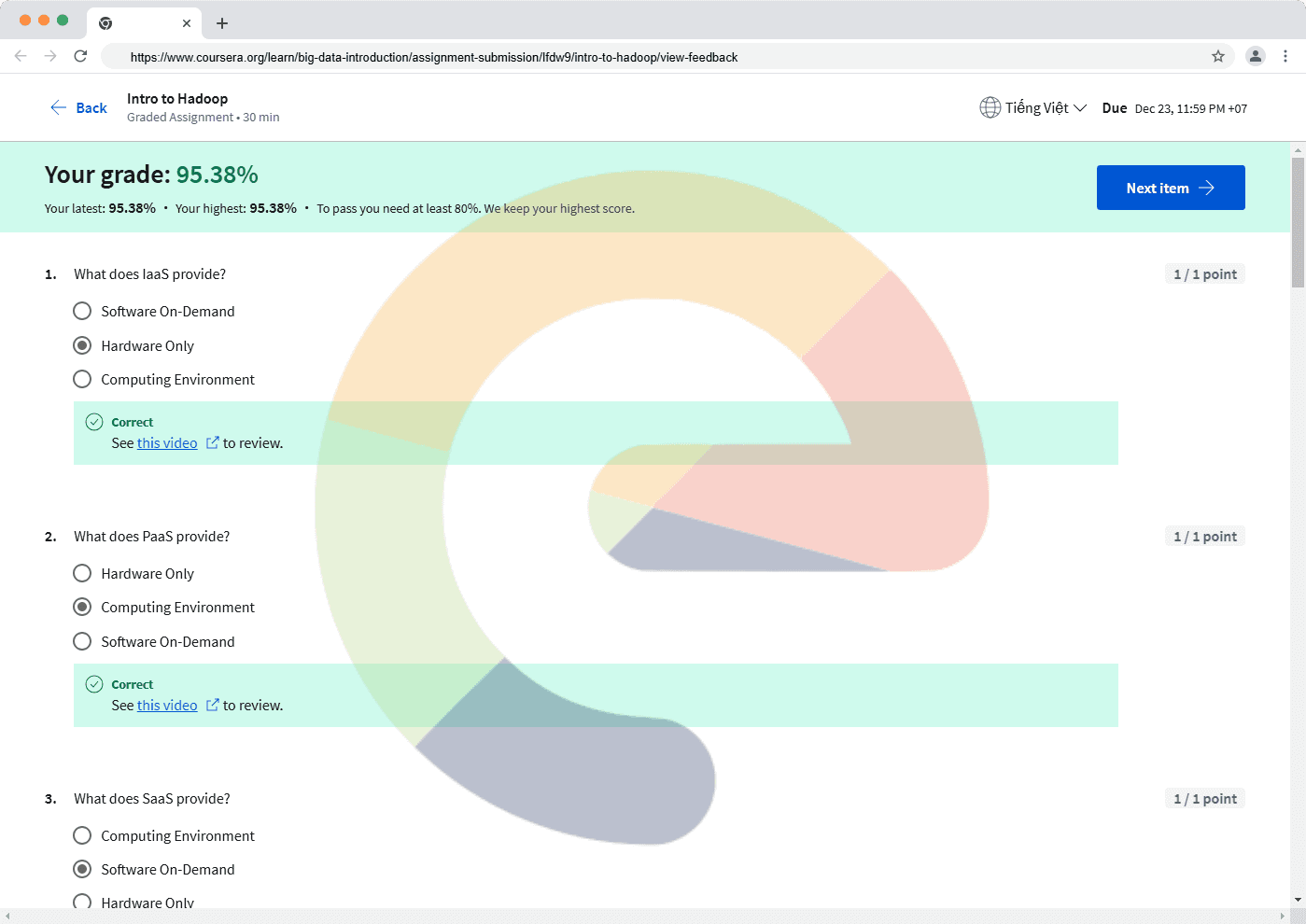
What does IaaS provide?
Computing Environment
Hardware Only
Software On-Demand
What does PaaS provide?
Software On-Demand
Computing Environment
Hardware Only
What does SaaS provide?
Software On-Demand
Computing Environment
Hardware Only
What are the two key components of HDFS and what are they used for?
NameNode for metadata and DataNode for block storage.
NameNode for block storage and Data Node for metadata.
FASTA for genome sequence and Rasters for geospatial data.
What is the job of the NameNode?
Coordinate operations and assigns tasks to Data Nodes
Listens from DataNode for block creation, deletion, and replication.
For gene sequencing calculations.
What is the order of the three steps to Map Reduce?
Map -> Reduce -> Shuffle and Sort
Shuffle and Sort -> Map -> Reduce
Shuffle and Sort -> Reduce -> Map
Map -> Shuffle and Sort -> Reduce
What is a benefit of using pre-built Hadoop images?
Quick prototyping, deploying, and validating of projects.
Guaranteed hardware support.
Quick prototyping, deploying, and guaranteed bug free.
Less software choices to choose from.
What are some examples of open-source tools built for Hadoop and what does it do?
Pig, for real-time and in-memory processing of big data.
Zookeeper, analyze social graphs.
Giraph, for SQL-like queries.
Zookeeper, management system for animal named related components.
What is the difference between low level interfaces and high level interfaces?
Low level deals with storage and scheduling while high level deals with interactivity.
Low level deals with interactivity while high level deals with storage and scheduling.
Which of the following are problems to look out for when integrating your project with Hadoop?
Advanced Alogrithms
Infrastructure Replacement
Task Level Parallelism
Random Data Access
Data Level Parallelism
As covered in the slides, which of the following are the major goals of Hadoop?
Enable Scalability
Latency Sensitive Tasks
Facilitate a Shared Environment
Provide Value for Data
Optimized for a Variety of Data Types
Handle Fault Tolerance
What is the purpose of YARN?
Allows various applications to run on the same Hadoop cluster.
Enables large scale data across clusters.
Implementation of Map Reduce.
What are the two main components for a data computation framework that were described in the slides?
Resource Manager and Container
Resource Manager and Node Manager
Node Manager and Applications Master
Node Manager and Container
Applications Master and Container