Using BigQuery in the Google Cloud Console - GSP406
D
A passionate full-stack developer from @ePlus.DEV
Search for a command to run...
A passionate full-stack developer from @ePlus.DEV
Great walkthrough—the emphasis on BigQuery's serverless architecture and how it handles partitioning under the hood really clicked for me, since that's where most traditional warehouses start to buckle. The step-by-step on loading and querying public datasets was particularly solid for getting hands-on fast.
Great walkthrough! I especially appreciated how you highlighted the serverless nature of BigQuery—no infrastructure to manage means I can focus purely on optimizing queries rather than worrying about cluster sizing. The step-by-step console navigation was also really clear for someone getting started with partitioning and clustering in the UI.
The first time I ran a multi-terabyte query in BigQuery, it felt almost broken because of how fast the results came back — it completely reset my expectations for what “scalable” SQL should feel like in a cloud environment.
As someone who often wrestles with on-prem query performance, the emphasis on BigQuery separating compute from storage really resonates. That architecture is a game-changer for ad-hoc analysis on large datasets. This is a solid primer on getting that first query running in the console.
Great overview of getting started. A key best practice is to always use the LIMIT clause when exploring a new, large table with a SELECT *. This prevents accidentally processing terabytes of data and keeps your query costs predictable.
Could you clarify how BigQuery manages resource allocation during concurrent queries? Specifically, what mechanisms are in place to ensure optimal performance when multiple users are querying large datasets simultaneously?
As someone who's wrestled with slow on-premise queries, the speed BigQuery achieves by separating storage and compute still feels like magic. This post perfectly highlights that core architectural advantage. Great overview of the "how" behind the performance.
Quick and practical tips to help users optimize tasks, improve skills, and solve common problems effectively across various areas like tech, lifestyle, productivity, and more.
Một bản tin giúp Developer cập nhật nhanh AI, Cloud, Open Source và những công nghệ đáng chú ý trong ngày. 📌 Executive Summary OpenAI công bố mười kết quả mới cho các bài toán lâu năm trong toán h

Một bản tin giúp Developer cập nhật nhanh AI, Cloud, Open Source và những công nghệ đáng chú ý trong ngày. 📌 Executive Summary GitHub thử nghiệm policy theo enterprise team, cho phép cấp thêm mode

Một bản tin giúp Developer cập nhật nhanh AI, Cloud, Open Source và những công nghệ đáng chú ý trong ngày. 📌 Executive Summary OpenAI giảm mạnh giá GPT-5.6 Luna và Terra, đồng thời chuyển Priority

Một bản tin giúp Developer cập nhật nhanh AI, Cloud, Open Source và những công nghệ đáng chú ý trong ngày. 📌 Executive Summary GitHub Copilot code review đã hỗ trợ chính thức Agent Skills và MCP s

Overview Vibe coding is an emerging software development practice that uses artificial intelligence (AI) to generate functional code from natural language prompts, accelerating development, and making
Storing and querying massive datasets can be time consuming and expensive without the right hardware and infrastructure. BigQuery is an enterprise data warehouse that solves this problem by enabling super-fast SQL queries using the processing power of Google's infrastructure. Simply move your data into BigQuery and let us handle the hard work. You can control access to both the project and your data based on your business needs, such as giving others the ability to view or query your data.
You access BigQuery through the Cloud Console, the command-line tool, or by making calls to the BigQuery REST API using a variety of client libraries such as Java, .NET, or Python. There are also a variety of third-party tools that you can use to interact with BigQuery, such as visualizing the data or loading the data. In this lab you access BigQuery using the Cloud Console.
Using BigQuery in the Cloud Console will give you a visual interface to complete tasks like running queries, loading data, and exporting data. This hands-on lab shows you how to query tables in a public dataset and how to load sample data into BigQuery through the Cloud Console.
In this lab you:
Query a public dataset
Create a custom table
Load data into a table
Query a table
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources are made available to you.
This hands-on lab lets you do the lab activities in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
Note: Use an Incognito (recommended) or private browser window to run this lab. This prevents conflicts between your personal account and the student account, which may cause extra charges incurred to your personal account.
Note: Use only the student account for this lab. If you use a different Google Cloud account, you may incur charges to that account.
Click the Start Lab button. If you need to pay for the lab, a dialog opens for you to select your payment method. On the left is the Lab Details pane with the following:
The Open Google Cloud console button
Time remaining
The temporary credentials that you must use for this lab
Other information, if needed, to step through this lab
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account.
If necessary, copy the Username below and paste it into the Sign in dialog.
student-04-75b49bee4db6@qwiklabs.net
You can also find the Username in the Lab Details pane.
Click Next.
Copy the Password below and paste it into the Welcome dialog.
JkHECCZLUrjr
You can also find the Password in the Lab Details pane.
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials.
Note: Using your own Google Cloud account for this lab may incur extra charges.
Click through the subsequent pages:
Accept the terms and conditions.
Do not add recovery options or two-factor authentication (because this is a temporary account).
Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.
Note: To access Google Cloud products and services, click the Navigation menu or type the service or product name in the Search field.
The BigQuery console provides an interface to query tables, including public datasets offered by BigQuery.
The Welcome to BigQuery in the Cloud Console message box opens. This message box provides a link to the quickstart guide and the release notes.
The BigQuery console opens.
In this section, you load a public dataset, USA Names, into BigQuery, then query the dataset to determine the most common names in the US between 1910 and 2013.
In the Explorer pane, click + ADD.
In ADD Data window, select Star a project by name.
Enter project name as bigquery-public-data and click STAR.
The project bigquery-public-data is added to your resources and you see the dataset usa_names listed in the left pane in your Explorer section under bigquery-public-data.
Click usa_names to expand the dataset.
Click usa_1910_2013 to open that table.
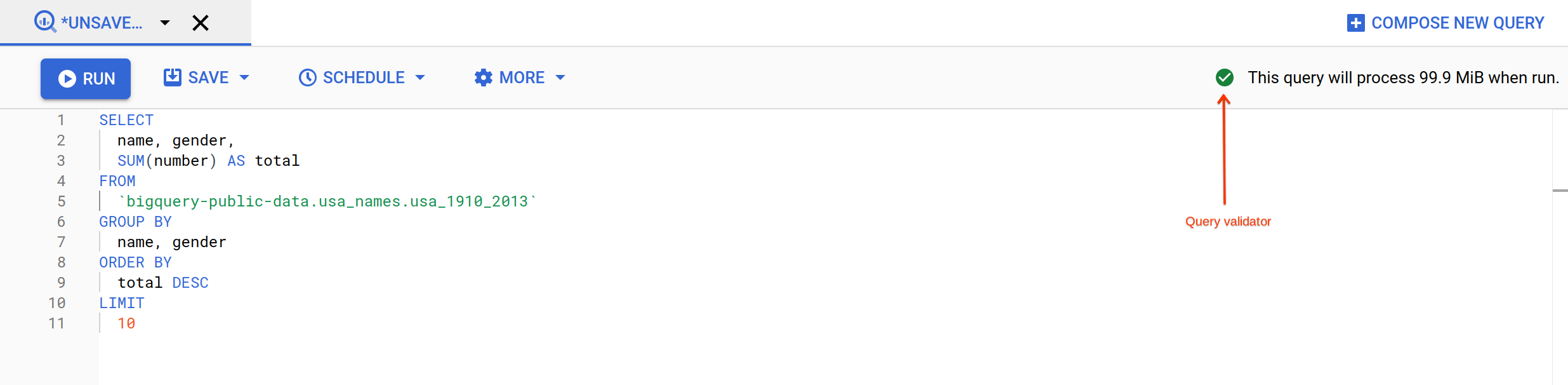
Query bigquery-public-data.usa_names.usa_1910_2013 for the name and gender of the babies in this dataset, and then list the top 10 names in descending order.
Click Query > In a new tab.
Remove the default query text in the Query editor.
Copy and paste the following query into the query EDITOR text area:
SELECT
name, gender,
SUM(number) AS total
FROM
`bigquery-public-data.usa_names.usa_1910_2013`
GROUP BY
name, gender
ORDER BY
total DESC
LIMIT
10
BigQuery displays a green check mark icon if the query is valid. If the query is invalid, a red exclamation point icon is displayed. When the query is valid, the validator also shows the amount of data the query processes when you run it. This helps to determine the cost of running the query.
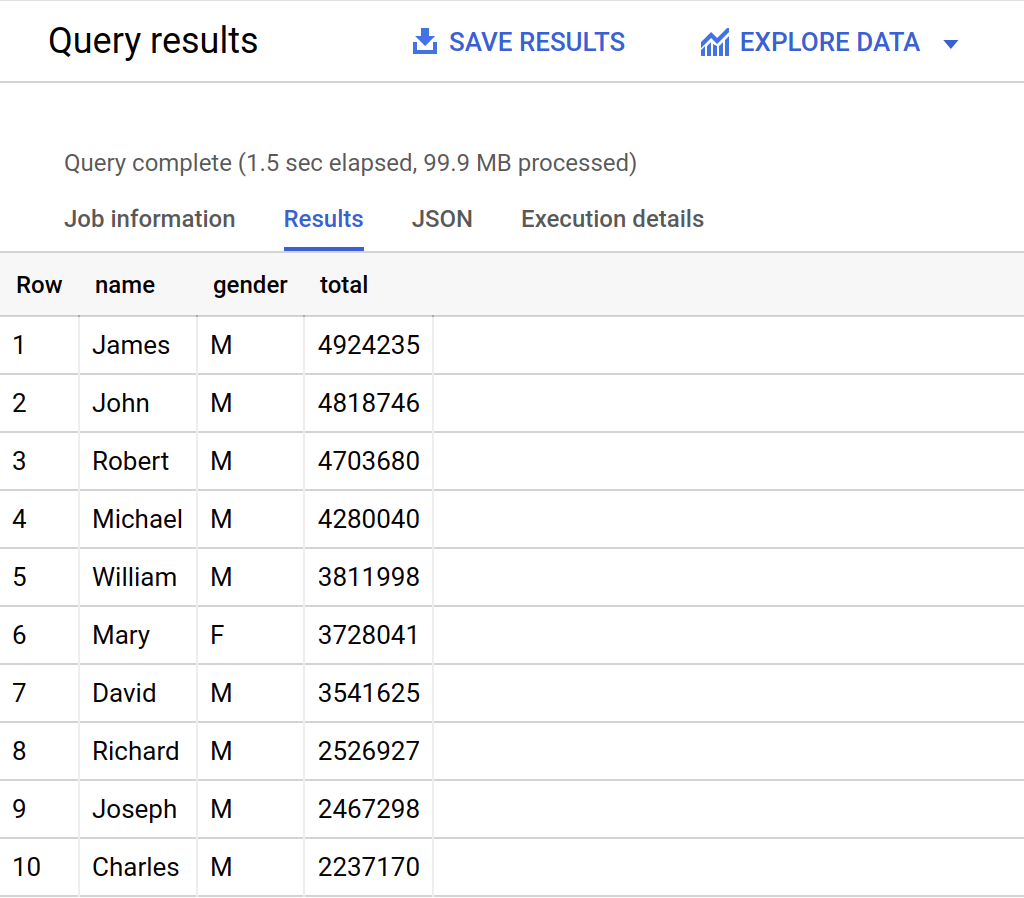
The query results opens below the Query editor. At the top of the Query results section, BigQuery displays the time elapsed and the data processed by the query. Below the time is the table that displays the query results. The header row contains the name of the column as specified in GROUP BY in the query.
Click Check my progress to verify the objective.
Query a public dataset
Check my progress
In this section, you create a custom table, load data into it, and then run a query against the table.
The file you're downloading contains approximately 7 MB of data about popular baby names, and it is provided by the US Social Security Administration.
Download the baby names zip file to your local computer.
Unzip the file onto your computer.
Open the file named yob2014.txt to see what the data looks like. The file is a comma-separated value (CSV) file with the following three columns: name, sex (M or F), and number of children with that name. The file has no header row.
Note the location of the yob2014.txt file so that you can find it later.
In this section, you create a dataset to hold your table, add data to your project, then make the data table you'll query against.
Datasets help you control access to tables and views in a project. This lab uses only one table, but you still need a dataset to hold the table.
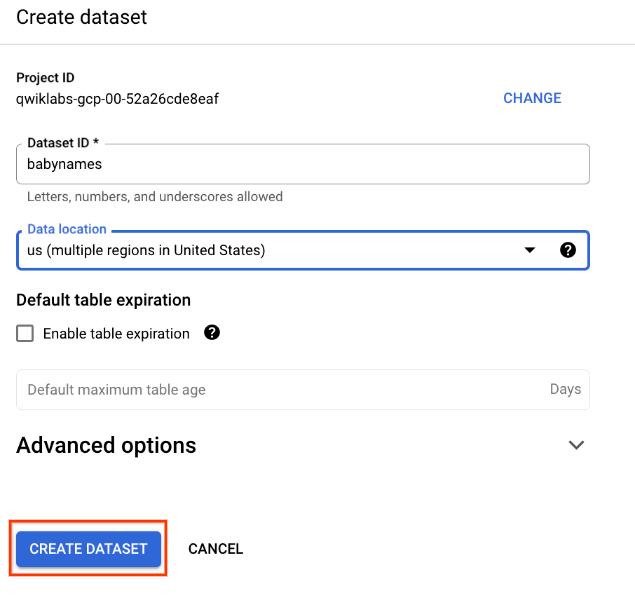
Back in the console, in the Explorer section, click on the View actions icon next to your project ID and select Create dataset.
On the Create dataset page:
For Dataset ID, enter babynames.
For Data location, choose us (multiple regions in United States).
For Default table expiration, leave the default value.
Currently, the public datasets are stored in the US multi-region location. For simplicity, place your dataset in the same location.
Click Check my progress to verify the objective.
Create a new dataset
Check my progress
In this section, you load data into the table you made.
Use the default values for all settings unless otherwise indicated.
For Create table from, choose Upload from the dropdown menu.
For Select file, click Browse, navigate to the yob2014.txt file and click Open.
For File format, choose CSV from the dropdown menu.
For Table name, enter names_2014.
In the Schema section, click the Edit as text toggle and paste the following schema definition in the text box.
name:string,gender:string,count:integer
Click Create table (at the bottom of the window).
Wait for BigQuery to create the table and load the data. While BigQuery loads the data, you can check the status from Personal history pane.
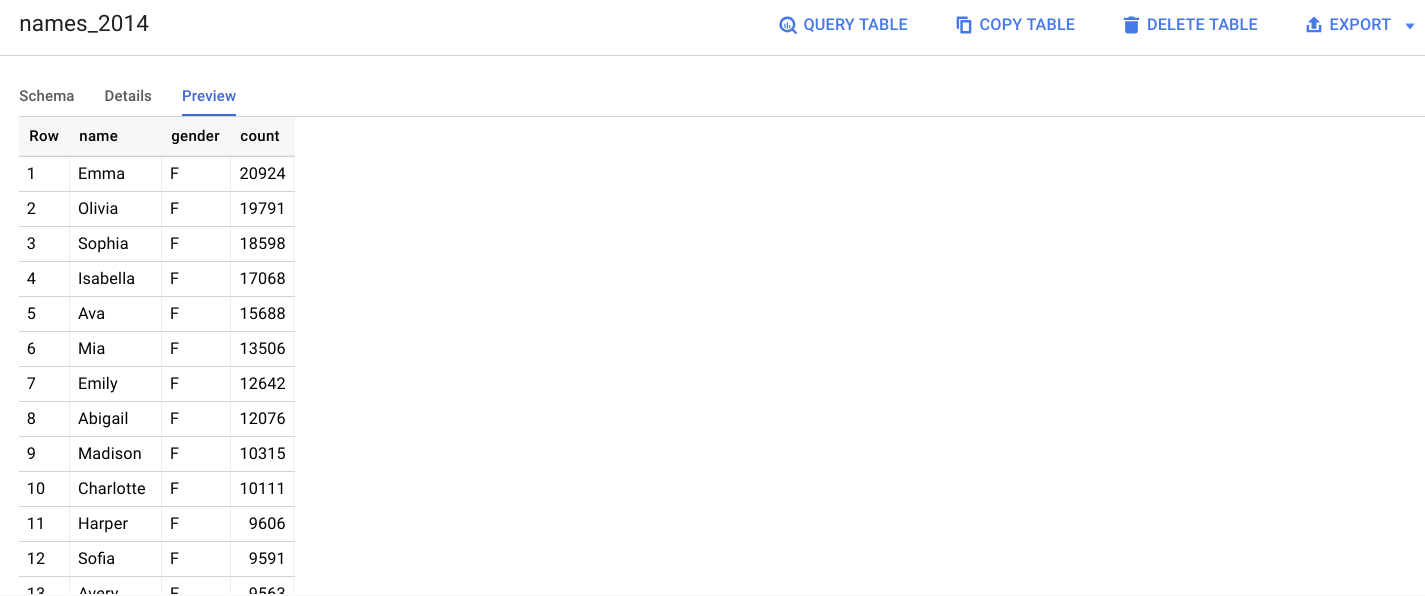
In the left pane, select babynames > names_2014 in the navigation panel.
In the details panel, click the Preview tab.
Quick quiz. You need a table to hold the datasetTrueFalse
Now that you've loaded data into your table, you can run queries against it. The process is identical to the previous example, except that this time, you're querying your table instead of a public table.
Click Query > In a new tab.
Remove the default query text in the Query editor.
Copy and paste the following query into the query EDITOR. This query retrieves the top 5 baby names for US males in 2014.
SELECT
name, count
FROM
`babynames.names_2014`
WHERE
gender = 'M'
ORDER BY count DESC LIMIT 5
Click Check my progress to verify the objective.
Query new dataset
curl -LO raw.githubusercontent.com/quiccklabs/Labs_solutions/master/Using%20BigQuery%20in%20the%20Google%20Cloud%20Console/quicklabgsp406.sh
sudo chmod +x quicklabgsp406.sh
./quicklabgsp406.sh